Inference
在Bayes Net中,Inference的目标是求解一个条件概率,也就是给出一些观测的变量( evidence ),计算查询变量( query variables ) 的后验概率
比如就表示着我们要求解当我们已经观察到事件e为真时,T为真的概率是多少?
我们首先能想到的最基础的方法就是,直接构造一个完整的概率联合表,然后我们用在Note11中提及到的Inference by Enumeration方法,先选择与evidence一致的行再求和最后归一化。但是这样做的问题也很明显,问题就在于第一步构造完整概率联合表上,假设每个变量都是binary,如果有n个变量那么就会有个rows,构造这样大的表很有难度。这就引出来了我们解决问题的方法Variable Elimination。我们在本讲引入的方法就是 Exact_Inference
Variable Elimination
首先我们需要定义Factor为一个未归一化的概率表,比如或者
Variable Elimination实例
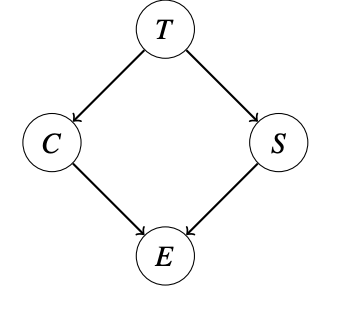
模型结构:
- T:是否拿宝藏
- C:是否触发陷阱
- S:是否触发蛇
- E:是否能逃脱 求,即已知逃脱成功,求拿到宝藏的概率
Step1:首先列出所有因子
Step2:Join所有包含C的factors以便下一步求和消除C 包含C的因子有:
- Join后得到新的factor: 也可以写成
Step3:消除C
用求和公式把C消除
Step4:Join所有包含S的factors以便下一步求和消除S 包含S的因子有:
- Join后得到新的factor
Step5:消除S
Step6:乘上剩余因子 还剩下一个,就可以得到
Step7:归一化
伪代码实现

与Enumeration的本质区别
Enumeration:
Variable Elimination:
Variable Elimination 把:
与求和无关的项提前移出求和符号
这大大减少了中间表的大小。 同时需要注意的是如果先消除 S,可能中间因子大小会不同。通过合理选择消除顺序,可以使最大因子尽可能小,从而降低计算复杂度。通常我们会采用贪心策略:每次选择“最小规模”的变量进行消除,其中规模可定义为当前涉及该变量的因子合并后的大小。这被称为“最小缺陷”或“最小边”启发式。