问题引入
我们在Note14中提及到了两种解决计算条件概率的方法,分别是Inference by Enumeration和Variable Elimination,这两种方法我们叫做精确推理( Exact_Inference ),在面临网格结构复杂还有变量众多的情况下,其计算量会变得巨大。所以说我们就引入了一种近似推理的方法—Sampling,通过牺牲精度来换效率。这种方法我们叫做 Approximate_Inference
Prior Sampling
这个方法是在通过拓扑顺序来依次在CPT中随机抽样,进而生成一个完整样本。再之后不断重复这个过程,出现大量样本后,某个事件出现的频率会收敛至它出现的真实频率.每个样本 (x₁, x₂, …, xₙ) 被抽中的概率正是网络的联合概率 P(x₁, x₂, …, xₙ),因为生成过程就是按照联合概率的分解(Chain rule)依次采样。 它的缺点也很明显,在面临计算条件概率的问题时,会浪费大量的样本,进而导致效率十分低下。如果样本很少时,又不能覆盖所有的情况
这里提醒一句,在Bayes Net中,一定一定不能把概率设为0.0,即便这个事件发生的概率很小,也应该赋予一个很小的概率值
实例
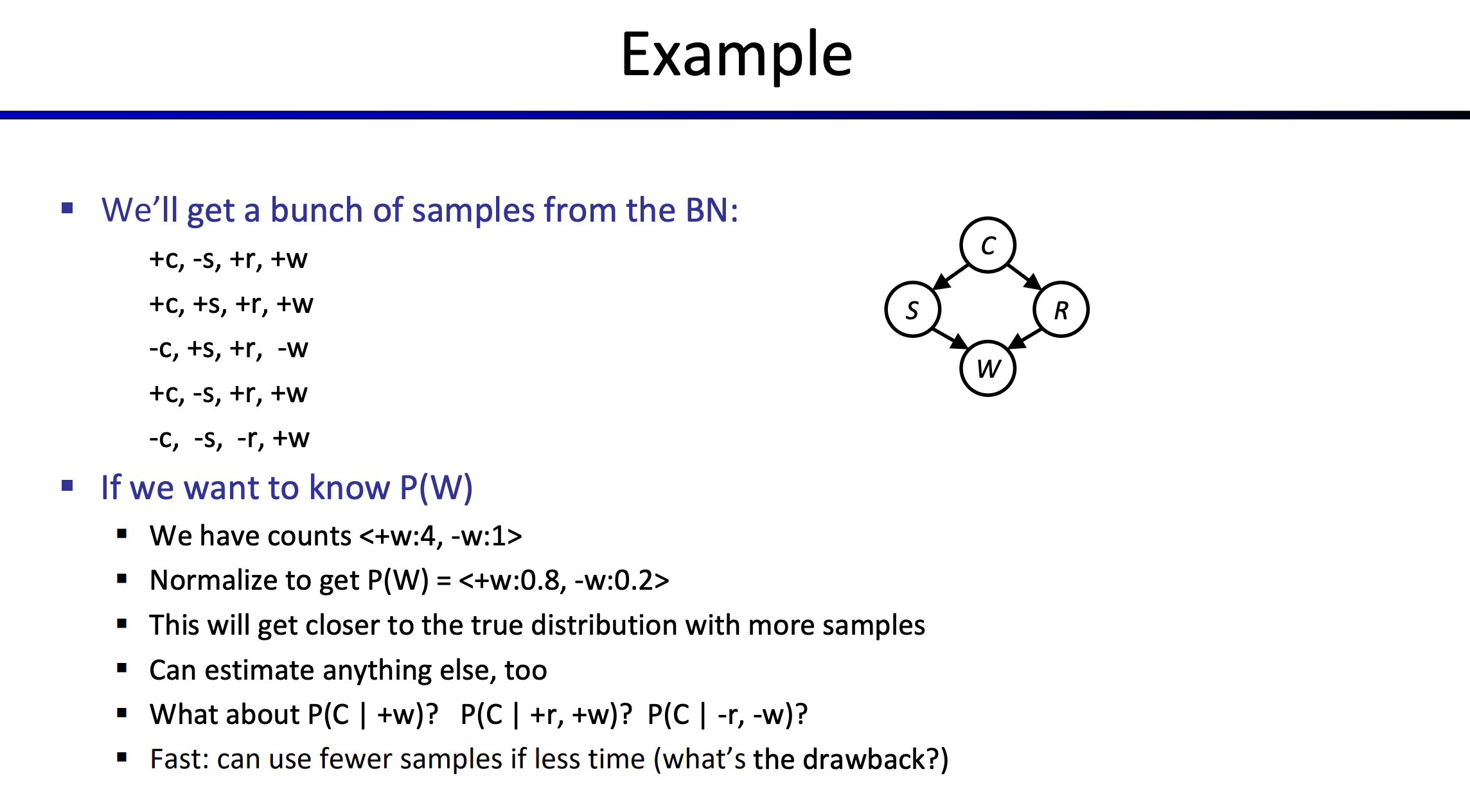
- 上面给定了五个样本,我们观察一下求解的概率。给定+w,我们只需要划掉第三个样本,剩下四个样本+C的概率为3/4,即得为3/4.
- 这里我们想一个问题,给定-w和-r的情况下,C的概率为多少?很明显五个样本没有这种情况,无法回答这个问题。
样本只是根据概率分布来随机抽取,有时候能完美覆盖我们所需要的问题,有时候又没有我们需要的样本。如果我们需要的情况足够罕见,那么我们很有可能很长时间都找不到这个样本.这是Sampling很明显的缺点
Python实现
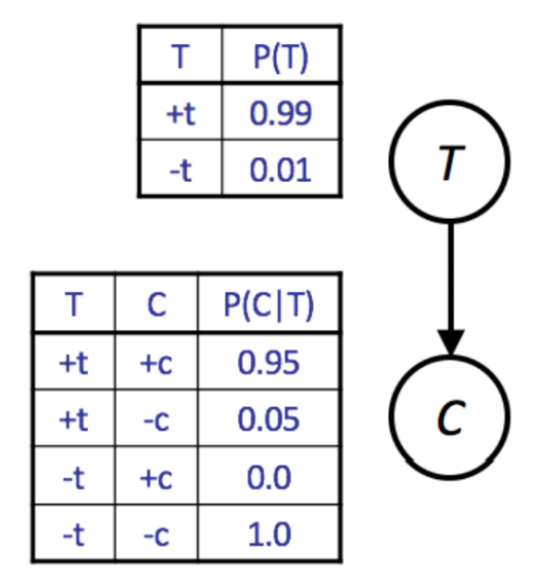
import random
def get_t():
if random.random() < 0.99:
return True
return False
def get_c(t):
if t and random.random() < 0.95:
return True
return False
def get_sample():
t = get_t()
c = get_c(t)
return [t, c]Rejection Sampling
这个方法相比Prior Sampling就改进了一点,就是在发现某个变量的取值和已知的evidence有冲突的话,直接舍弃当前的样本
步骤(以查询 P(C | T=false) 为例):
- 按照拓扑顺序采样:先采样 T。
- 如果 T 的值不等于 false(即证据要求 T=false),则拒绝整个样本,回到步骤 1 重新开始。
- 如果 T=false,继续采样 C。
- 最终得到一个符合证据的样本 (T=false, C=?)。
- 重复多次后,统计 C 的取值频率,即为 P(C | T=false) 的近似。 我们仍然需要抛弃我们的大量样本,但至少我们避免了在冲突的样本上少花了点算力
我个人在考虑这种算法是想到了一个问题,
在
Rejection Sampling中,当我发现与evidence不符合的样本的时候,我做的行为是直接舍弃这个样本。难道舍弃这种行为不会出现和Likelihood Weighting算法出现的样本不符合概率联合分布的情况吗
答案是不会,我们观察一下条件概率,当我们给定+w时我们注意的是C出现的频率。Rejection Sampling所做的行为是舍弃掉-w出现的情况,不影响给定+w下C出现的频率。;观察拓扑顺序对这个方便理解一点
Likelihood Weighting
我们在Rejection Sampling的思想很有参考价值,当我们发现一些和evidence不符合的情况立马舍弃样本。但是当我们观测到证据变量的取值概率本身就很小,那么就也会产生浪费大量样本的问题。
为了解决这个问题,我们在这里新增一个方法,这个方法成功从根源上解决了产生不符合的样本的情况。当我们发现与evidence不符合的话,我们选择保留而不是舍弃。但是如果保留了与evidence相违背的样本,生成样本的过程中就不符合联合分布。为了避免样本产生偏离联合分布的情况,我们为每个样本引入一个权重的概念,权重的计算公式为证据变量还有其在父节点被observed的情况下的乘积,这样以来我们对于不合理的样本分配小的权重,给合理的样本赋予大权重
之所以有样本权重,是因为我们操纵的这些节点,实际上只有很小的概率能落到我们想要的方向上面,这种概率需要在某个方向体现出来,所以说就是权重的来源
我们对于非证据变量( evidence),投硬币来决定其值来观察其自然结果。对于证据变量我们直接固定其值,并根据其父节点在observed的情况下的概率更新权重。
Likelihood Weighting不同节点的内在联系
- 我们需要意识到的是,因为我们固定
evidence是固定出现的,evidence相关的条件概率并不会影响这个样本出现的概率。只有evidence之外的节点才会影响该样本的概率。 - 而我们的权重是只有概率节点的条件概率的乘积,这两个乘积没有任何交集,但它们的乘积就是联合概率
我们在这里回顾一下
Bayes Net的联合概率计算公式,联合概率就是所有节点的条件概率的乘积。 假设一个网格,A -> B -> C,假设evidence为C = True,联合分布为
其中样本生成概率为
其中权重为
上面二式乘积正为联合概率
伪代码实现

Gibbs Sampling
我们需要思考一个有关Likelihood Weighting的问题:Fire代表火灾,Alarm代表警报响,他们的网格关系为F -> A
| P(F) | |
|---|---|
| +F | 0.01 |
| -F | 0.99 |
| F | A | |
|---|---|---|
| +F | +A | 0.99 |
| +F | -A | 0.01 |
| -F | +A | 0.01 |
| -F | -A | 0.99 |
假设我们想了解,用Likelihood Weighting算法来进行的话,我们强制固定+A,然后在F中投硬币。有99%的概率会出现-F +A的样本,我们浪费了大量算力来找一个罕见样本+F +A,这就是我们为什么需要Gibbs Sampling |
Markov Blanket
首先需要介绍的一个概念是马尔可夫毯:一个变量的马尔可夫毯包括它的父节点、子节点、以及子节点的其他父节点。在给定马尔可夫毯的条件下,该变量与网络中所有其他变量条件独立。因此,重新采样时只需考虑它的马尔可夫毯。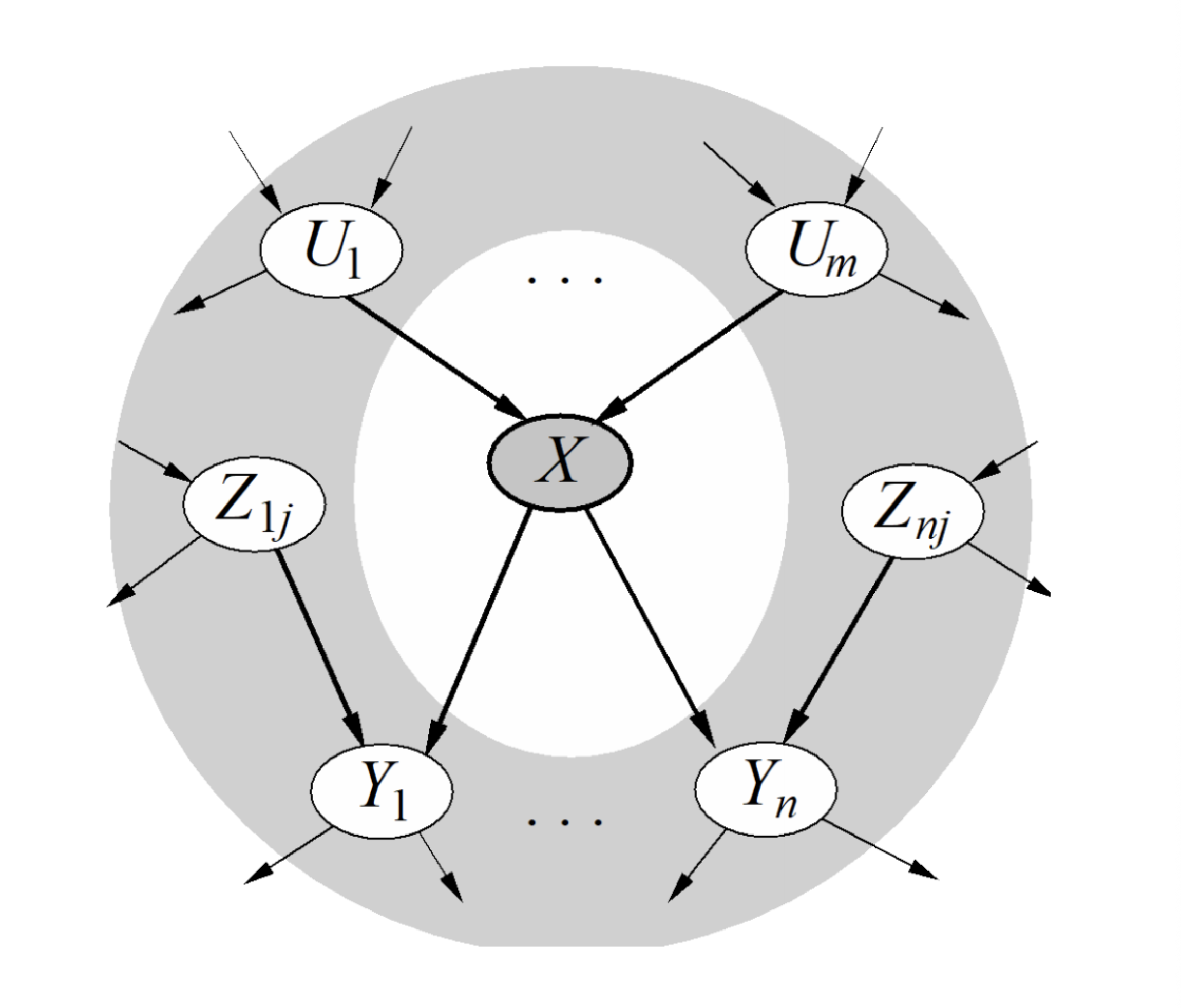
步骤
- Step 0:Random initialization(随机初始化)
一开始完全乱填,不看 CPT:
- t=true,c=true,s=false,e=true
- Step 1:Repeated local resampling(反复局部重采样)
循环做下面的事情:
- 随机挑一个变量(比如挑到 S)
- 把它“清空”(当作 S=)
- 计算它在当前其它变量取值下的条件分布:
- 按这个分布重新给 S 抽一个值 然后继续挑另一个变量,重复同样的过程。
伪代码
