问题引入
我们在先前提及到了精确推理( Exact_Inference ),当我们面临的问题状态空间特别大的时候,我们的计算会变得特别复杂且繁琐。我们这里就引入了Particle Filtering,这是一种用来解决HMM的近似推理方法,非常类似于Bayes Net中的采样,同时它也是一种更高效的Approximate Inference方法。它和Forward Algorithm解决的是同一个问题,都是在计算
Particle Filtering
基本概念
- Particles: 一个粒子是一个样本,每个粒子代表着对当前真实状态的一个猜测,或者说是状态空间中的一个样本点
- Belief distribution: 我们在Note17中提及到过,这是信念分布,由粒子的分布近似表示
- 总的来说,某个状态里的粒子越多,我们就越相信真实状态在那里
基本过程
先来看一张PPT就能大概了解个大概.我们在初始阶段准备一组粒子,作为最初的belief approximation
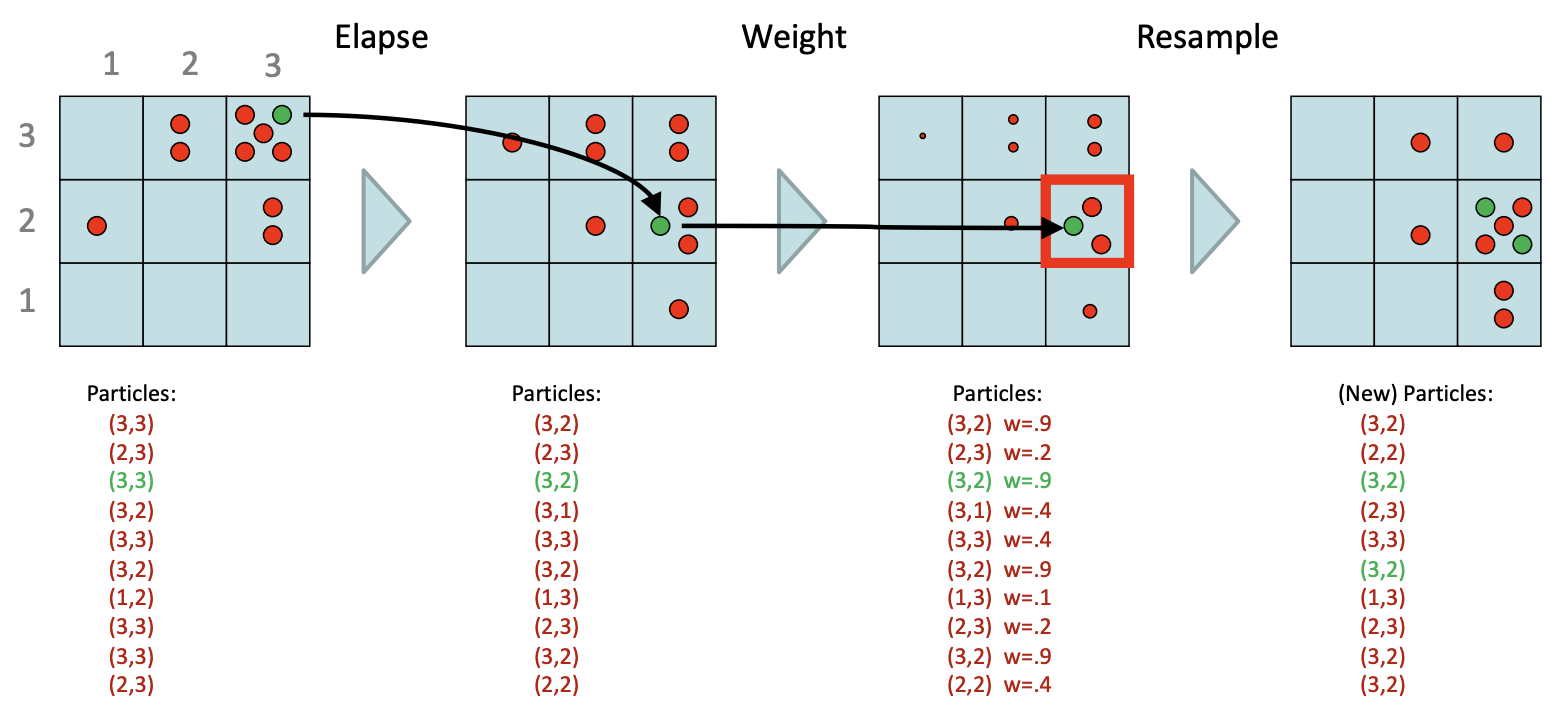
Step1: Time Elapse Update
- 根据转移模型中更新每个粒子的状态,这一步非常像
Bayes net中的Prior sampling 假设粒子当前状态为,转移模型为
| 14 | 15 | 16 | |
|---|---|---|---|
| 概率 | 0.1 | 0.8 | 0.1 |
| 所以说为每个可能的下一个状态分配一个区间 |
- 14: [0, 0.1)
- 15: [0.1, 0.9)
- 16: [0.9, 1) 我们随机生成一个数字r = 0.467,这个数字落在区间[0.1, 0.9)中,因此粒子保持为15,其它粒子同理
Step2: Observation Update
在Step 2中我们运用的是sensor model,这个在先前的Note17第一次提及到。利用当前观测evidence来判断哪些粒子更可信一些,我们运用的是,也就是如果真实状态是,观测到的概率是多少?我们运用这一点判断我们观测的合理性:
- 为每个粒子计算权重
- 按状态汇总权重
- 如果总权重为 0,重新初始化所有粒子
- 否则,归一化权重,形成概率分布
- 从这个分布中重新采样粒子
Observation Update示例
假设观测到,sensor model 为:
- 正确预测的概率为 80%
- 其他 10 种状态各占 2% 于是10个粒子的权重分别是:
[0.02, 0.8, 0.8, 0.02, 0.02, 0.02, 0.8, 0.02, 0.02, 0.02]再按状态汇总,总权重就是:
| 状态 | 10 | 11 | 12 | 13 | 14 | 15 | 17 |
|---|---|---|---|---|---|---|---|
| 权重 | 0.2 | 0.02 | 0.04 | 2.4 | 0.04 | 0.04 | 0.02 |
归一化后 → 13的概率大约是0.9449,这表示我们在当前观测下,状态13明显是最合理的解释 这时候再进行重采样,所有粒子基本都落在了13区间上,表示我们信念分布基本在13上
Particle Filtering与Forward Algorithm的关系
他们解决的是同一个问题:
Forward Algorithm
- 是 exact inference
- 维护的是完整概率表
- 状态空间一大,计算就会变重
Particle Filtering
- 是 approximate inference
- 维护的是一组粒子
- 当状态空间很大时更实用
- 精度取决于粒子数