Markov Decision Processes
MDP的要素
- 状态集合S
- 动作集合A
- 起始状态
- 终止状态( 可选 )
- 转移函数 T( s, a, s’ ) — 表示在状态 s 执行动作 a 后到达状态 s′ 的概率
- 奖励函数R( s, a, s’) — 表示在状态 s 执行动作 a 后到达状态 s′ 所获得的即时奖励
- 折扣因子( 可选 )
Example
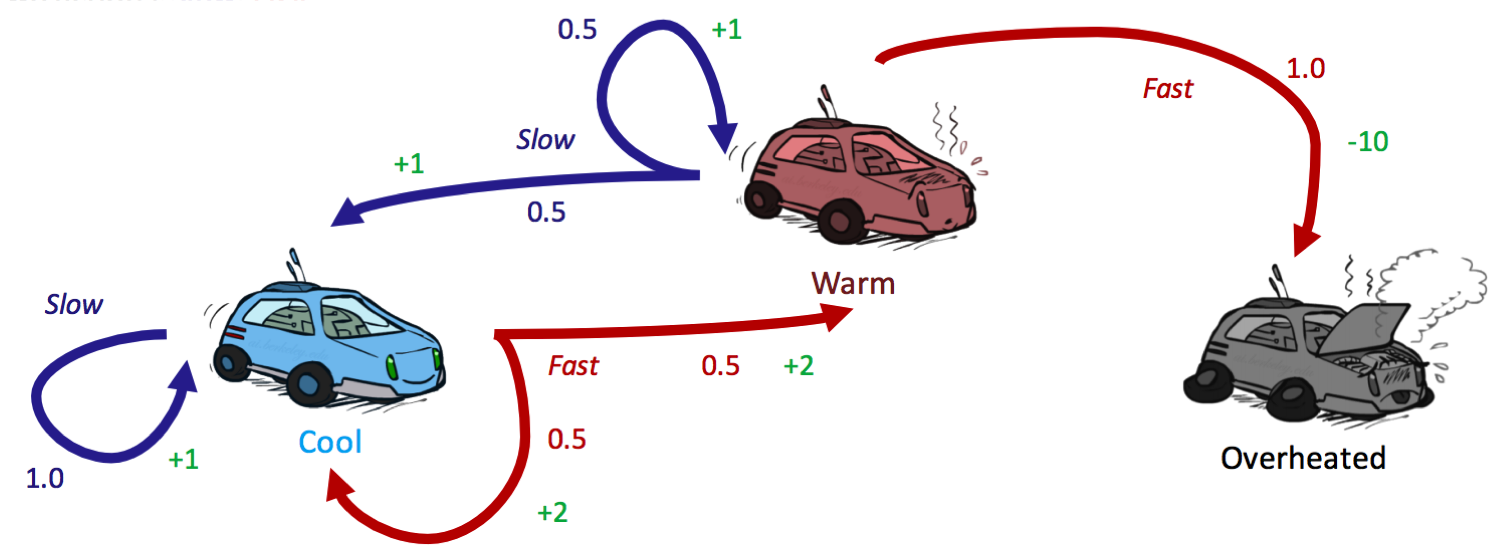
状态与动作
状态:{cool, warm, overheated}(overheated 为终止状态) 动作:{slow, fast}
转移函数和奖励函数
- Transition Function: T (s, a, s′ )
- T (cool, slow, cool) = 1
- T (warm, slow, cool) = 0.5
- T (warm, slow, warm) = 0.5
- T (cool, f ast, cool) = 0.5
- T (cool, f ast, warm) = 0.5
- T (warm, f ast, overheated) = 1
- Reward Function: R(s, a, s′ )
- R(cool, slow, cool) = 1
- R(warm, slow, cool) = 1
- R(warm, slow, warm) = 1
- R(cool, f ast, cool) = 2
- R(cool, f ast, warm) = 2
- R(warm, f ast, overheated) = −10i
未折扣的效用函数
我们可以数学化表示最终要最大化下列的效用函数( utility function )
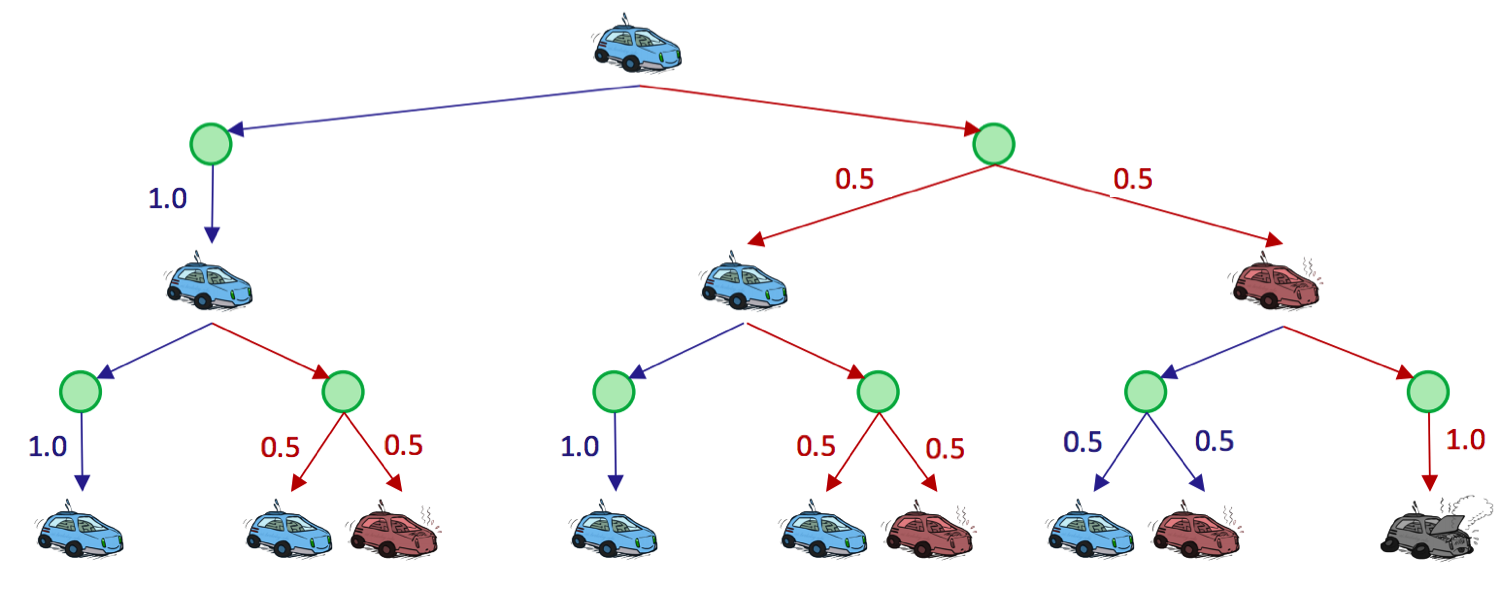
Q-states
MDP也能转化称搜索树,不确定性的节点叫做Q-states,对应下面的搜索树图中的绿色圆圈。Q-states非常类似于Expectimax算法,它们都用概率来处理环境的不确定性,这一点和Expectimax算法中的机会节点( chance node )十分相近
Finite Horizons and Discounting
引入问题:若允许无限步及,某些策略( 例如一直执行安全动作 )可能会获得无限期的正回报
Finite Horizons
直接限定代理能行动的最大步数 n,可以理解为智能体( agent )的lifetime
Discounting
将 t 时刻的奖励乘以 γᵗ,从而把“远期奖励”折算得更小 原文内容
Concretely, with a discount factor of γ, taking action at from state st at timestep t and ending up in state st+1 results in a reward of γ t R(st , at , st+1 ) instead of just R(st , at , st+1 ).未折扣的效用函数( additive utility )
折扣的效用函数( discounted utility )
其中可以证明只要满足|γ| < 1,该函数为有界函数
其中为马尔可夫决策过程中任何给定时间步所能获得的最大可能奖励值, 现实中通常选 0 < γ < 1
马尔可夫性 Markovianess
可以简单理解为给定当前状态s ( 以及当前动作a ) 后未来的下一步action概率分布不受过去的任何行为影响,即只需要当前状态即可预测未来行为
其中转移函数 就是在就是在描述这一种的无记忆行为
策略( Policy )与目标
- 策略(policy):S → A,把状态映射到动作(可以是确定性或随机化策略)
- 目标:找到最优策略 ,使得从任意起始状态出发,期望(折扣)累计回报最大化。可以理解为求解 MDP = 求策略
Bellman方程
内容需知-价值函数与 Q 值的定义
原文内容
• The optimal value of a state s, U*(s) – the optimal value of s is the expected value of the utility an
optimally-behaving agent that starts in s will receive, over the rest of the agent’s lifetime. Note that
frequently in the literature the same quantity is denoted with V*(s).
• The optimal value of a Q-state (s, a), Q*(s, a) - the optimal value of (s, a) is the expected value of the
utility an agent receives after starting in s, taking a, and acting optimally henceforth.- 最优状态值函数 U*(s):从状态 s 开始,按最优策略能获得的期望折扣总奖励。
- 最优Q值 Q*(s,a):在状态 s 执行动作 a后,再按最优策略能获得的期望折扣总奖励。 两者之间的关系如下
Bellman Equation
结合上面两式可以得到如下方程
上面方程可以理解为在当前状态s下,评估了每个动作a的期望收益,其中通过后继s’概率来加权,权重再乘( 立即奖励+折扣后的后续最优价值 )
Q1:难道s采取a动作到s’这不已经标定了只有这一种过程吗,为什么还要求和
一定要记住MDP的核心前提即环境是随机的,求和是在对多种可能结果做加权平均