开始上强度了,Note8主要是在讲解MDP问题的解决方法,所以说要记住这个Note8围绕的是求解policy(状态到动作的映射)
Value Iteration
初步思路框架
首先想到的第一个方法就是评估每个状态的utility,之后用Bellman方程来求解Q*( s, a ),即最优Q值,在状态 s 执行动作 a后,再按最优策略能获得的期望折扣总奖励。最优Q值里面就带有了动作信息,从而求出最佳policy
一定要注意的是,Bellman方程的适用范围只有最优解即带有* 的变量
实现过程
在这个过程之中,每个状态的utility是通过动态规划的思想逐步更新的,直到收敛到最优值U*(s) 在进行公式表达之前,需要定义为从状态s出发,走k布所能获得的效用值
- 初始设定: = 0,因为走0步不能或者任何奖励
- 迭代规则:
证明值迭代最终会收敛的过程省略,在原Note中有详细证明过程
Value Iteration示例
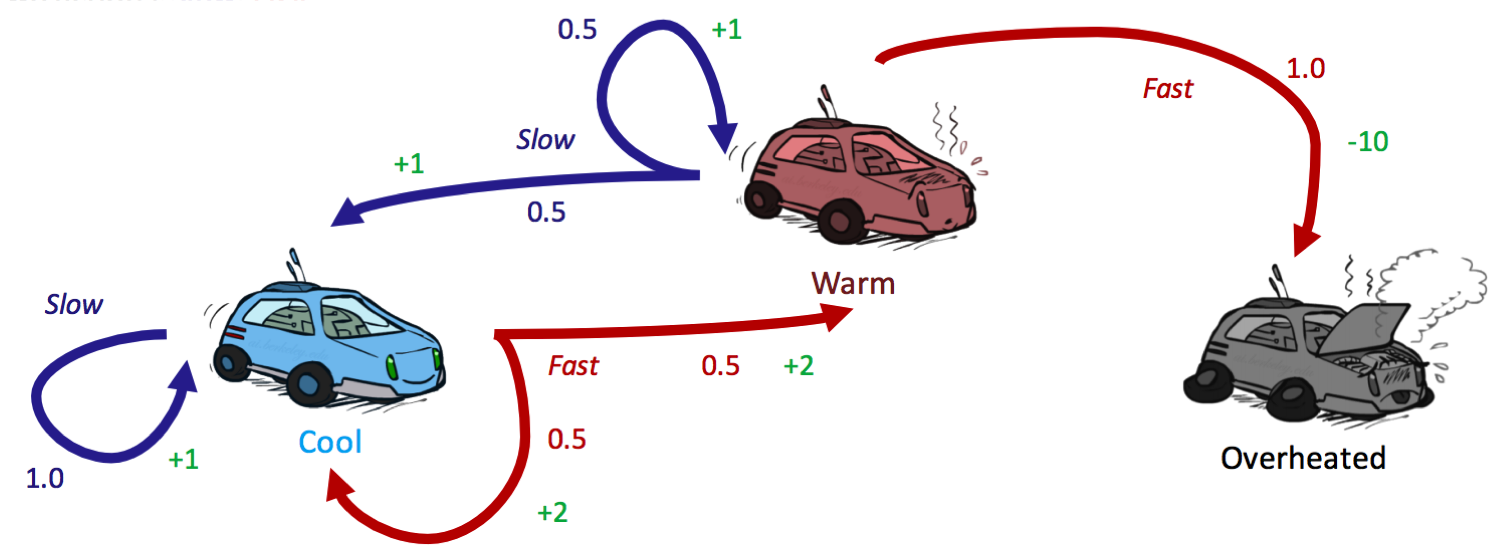 折扣因子γ = 0.5,最开始的初始状态所有状态的都是 = 0,所以可以得到下面的表格
折扣因子γ = 0.5,最开始的初始状态所有状态的都是 = 0,所以可以得到下面的表格
| cool | warm | overheated | |
|---|---|---|---|
| 0 | 0 | 0 | |
| 第一轮迭代计算如下 |
| cool | warm | overheated | |
|---|---|---|---|
| 0 | 0 | 0 | |
| 2 | 1 | 0 | |
| 再进行下一轮的时候和这一轮一模一样 |
| cool | warm | overheated | |
|---|---|---|---|
| 0 | 0 | 0 | |
| 2 | 1 | 0 | |
| 2.75 | 1.75 | 0 |
这里对于公式里折扣的那一部分一定要理解清楚,再观察一遍迭代公式
其中 这一部分并不是发生在前面的,可以根据状态变化看出来,s采取动作a变成了状态s’,在状态s时还有k+1步未走,到达状态s’后剩余k步,这里动态规划复用的是 来表明下一时刻的未来价值。 举个例子来说,在算的时候,假设采取的动作的是slow,表示的是站在的角度,下一步又回到了cool,从那一刻开始你还能再拿到的最佳期望收益,所以说不是已经发生的收益,而是未来的收益。我最开始只看例子误解了公式,因为折扣因子是和相乘的,让我误以为原本意图是给过去的效用上折扣,实际上不是
Policy Extraction
这一步就到了我在value iteration中提及到的求完Q*( s, a )后提取最优策略既,下面是公式
原文中的一句话值得斟酌一下,揭露了MDP与expectimax搜索树之间的关系,概率分支的出现正是因为MDP的随机环境,在ecpectimax里面可以用机会节点来表示
Storing only each U ∗ (s) means that we must recompute all necessary Q-values with the Bellman equation before applying argmax, equivalent to performing a depth-1 expectimax.上述内容可以用下面的树来表达
Expectimax搜索树
s
/ \
slow fast ← MAX(选动作)
| |
chance chance ← 概率分支
| |
s' s'Q-Value Iteration
这里就提及到了另外一种更直接地解决MDP问题的方法,就是不再计算状态的效用值了,直接来计算Q( s, a ),这样就直接用包含策略信息的Q值来求得policy,基本迭代思路还是和之前的大差不差
Q值迭代到最后也一定是收敛的,和Value Iteration的证明方法几乎一样。实际上,只要折扣因子 γ < 1, 那么iteration的结果到最后就会收敛。更新完Q*( s, a )后,直接用公式提取最优策略
Policy Iteration
问题引入
引入Policy Iteration的问题就是,如果用value iteration,其时间复杂度过高。value iteration共有三层循环,对每个状态 |S|, 对每个动作 |A|, 对每个下一状态 |S′|, 综合在一起时间复杂度就是 所以说为了避免大量的功夫浪费在value iteration的不断数值计算上,就着重于策略的改进
核心思想
固定一个策略 → 算这个策略的真实价值 → 用这个价值改进策略 → 重复直到策略不发生变化实现过程
首先需要回顾一下Value Iteration中U的角标的含义,在这里表示的是从状态s出发,一直采用策略走k步所能获得的效用值。在实现之前需要我们定义一个最初的policy,此时我们公式内容就不需要max了。核心公式如下
从本质上来说,这是一个方程组,因为每个状态包含一个未知数, 每个状态都只有一个等式,一共有s个方程,所以说可以一次性解出来所有的值。解出来真实价值之后,我们就到了第三步,就是用这个价值来改进策略,策略改进的公式如下
如何来判断当前policy是不是最好呢?
Policy Iteration示例
依旧是汽车这个图,首先初始化policy为总是slow
| cool | warm | overheated | |
|---|---|---|---|
| slow | slow | - | |
| 我们进行第二部计算策略真实价值,套用公式可以得到方程组 |
解出结果可以得到策略真实价值
| cool | warm | overheated | |
|---|---|---|---|
| 2 | 2 | 0 | |
| 然后进行第三步,用价值改变策略 |
重复上述步骤最终可以得到Policy最终收敛,迭代完毕
| cool | warm | |
|---|---|---|
| slow | slow | |
| fast | slow | |
| fast | slow |