Q1.Value Iteration
第一个问题是最基础的值迭代实现,这个问题没有什么难度,主要就是一边看着公式一遍敲代码复现。可以先回顾一下Note8中的Value Iteration框架.唯一唯一需要注意的就是需要使用的是batch版本,而不是online版本。这里是前面Note没有提及到的概念,用图片来理解一下会更好一点
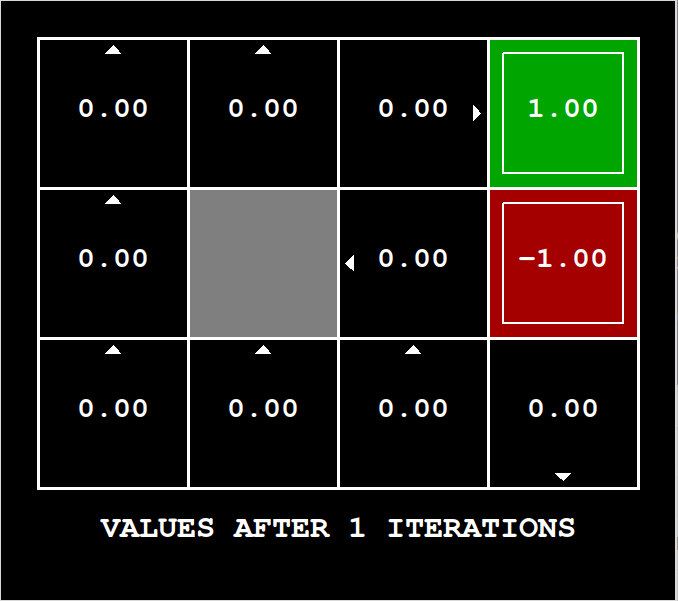
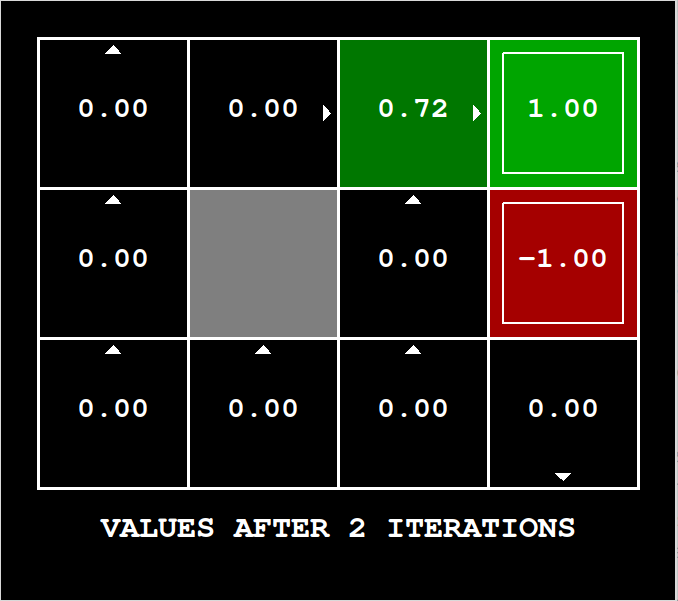
这个问题用的数据结构是
Counter,它的底层容器是哈希表。Counter十分类似于Dictionary,它只是新增了一条设定,即所有初始值都为0。上图中一张图就可以理解为一个Counter,每个状态都有对应的Value,就和键值对应一样
所谓online版本,就是在某轮循环更新某个状态时,你用了本轮其它状态的值。可以参考图一,假设遍历的第一个状态是效用值为1的状态,1左边的方格在第一轮也会受到效用值1的影响。这样就是偷看了本轮新值。 图一到图二经历的过程就是batch版本,这个过程是由图一推演出来的,而并非参考第二轮迭代的新值。这样就严格遵循了是由推演出来的定式
代码实现
def runValueIteration(self):
"""
Run the value iteration algorithm. Note that in standard
value iteration, V_k+1(...) depends on V_k(...)'s.
"""
"*** YOUR CODE HERE ***"
for i in range(self.iterations):
newValues = util.Counter()
for state in self.mdp.getStates():
if self.mdp.isTerminal(state):
newValues[state] = 0
continue
actions = self.mdp.getPossibleActions(state)
if not actions:
newValues[state] = 0
continue
qValues = []
for action in actions:
q = self.computeQValueFromValues(state, action)
qValues.append(q)
newValues[state] = max(qValues)
self.values = newValues
def getValue(self, state):
"""
Return the value of the state (computed in __init__).
"""
return self.values[state]
def computeQValueFromValues(self, state, action):
"""
Compute the Q-value of action in state from the
value function stored in self.values.
"""
"*** YOUR CODE HERE ***"
qValue = 0
transitions = self.mdp.getTransitionStatesAndProbs(state, action)
for nextState, prob in transitions:
reward = self.mdp.getReward(state, action, nextState)
qValue += prob * (reward + self.discount * self.getValue(nextState))
return qValue
util.raiseNotDefined()
def computeActionFromValues(self, state):
"""
The policy is the best action in the given state
according to the values currently stored in self.values.
You may break ties any way you see fit. Note that if
there are no legal actions, which is the case at the
terminal state, you should return None.
"""
"*** YOUR CODE HERE ***"
if self.mdp.isTerminal(state):
return None
actions = self.mdp.getPossibleActions(state)
if not actions:
return None
bestAction = None
bestValue = float('-inf')
for action in actions:
q = self.computeQValueFromValues(state, action)
if q > bestValue:
bestValue = q
bestAction = action
return bestAction
util.raiseNotDefined()整体思路并不难,Coding过程只需要注意一下不要遗漏处理
No Leagal Action的情况就可以了
Q2.Policies
Q2问题更简单了,这就是凭直觉调节参数的题目,需要注意的是有三个变量
- Discount
- 如果更偏重眼前的利益,就应给在
Value Iteration中给更远的奖励值上更小的折扣 - 如果想要长远的奖励值,就只能让其折扣更大,避免长期奖励被过度削弱
- 如果更偏重眼前的利益,就应给在
- Noise
- 如果游走在Cliff附近,就要调小噪音避免不确定行为发生
- 如果绕远路,则鼓励Exploration,多去探索可能性
- LivingReward
- 如果目的是一直不退出,则将存活奖励调大
- 反之则调小
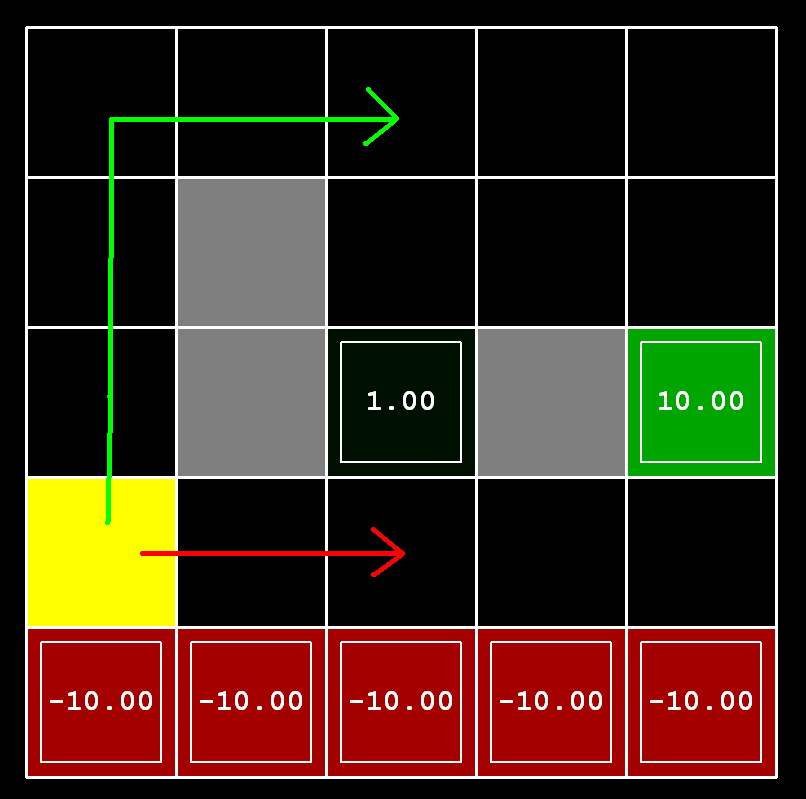
代码实现
def question2a():
"""
Prefer the close exit (+1), risking the cliff (-10).
"""
answerDiscount = 0.3
answerNoise = 0.0
answerLivingReward = 0.0
return answerDiscount, answerNoise, answerLivingReward
# If not possible, return 'NOT POSSIBLE'
def question2b():
"""
Prefer the close exit (+1), but avoiding the cliff (-10).
"""
answerDiscount = 0.3
answerNoise = 0.2
answerLivingReward = 0.0
return answerDiscount, answerNoise, answerLivingReward
# If not possible, return 'NOT POSSIBLE'
def question2c():
"""
Prefer the distant exit (+10), risking the cliff (-10).
"""
answerDiscount = 0.8
answerNoise = 0.0
answerLivingReward = 0.0
return answerDiscount, answerNoise, answerLivingReward
# If not possible, return 'NOT POSSIBLE'
def question2d():
"""
Prefer the distant exit (+10), avoiding the cliff (-10).
"""
answerDiscount = 0.8
answerNoise = 0.3
answerLivingReward = 0
return answerDiscount, answerNoise, answerLivingReward
# If not possible, return 'NOT POSSIBLE'
def question2e():
"""
Avoid both exits and the cliff (so an episode should never terminate).
"""
answerDiscount = 0.9
answerNoise = 0.0
answerLivingReward = 1
return answerDiscount, answerNoise, answerLivingReward
# If not possible, return 'NOT POSSIBLE'Q3.Q-Learning
Q3稍微有一点复杂但是难度并不大,主要就是围绕着Q-Learning的实现来Coding。其中需要完成的函数共有五个,唯一需要注意的点就是在computeActionFromQValues函数中,面临着相同状态同样最好的QValues,需要用到random.choice()来进行随机选择,要不然会不能通过autograder
代码实现
class QLearningAgent(ReinforcementAgent):
"""
Q-Learning Agent
Functions you should fill in:
- computeValueFromQValues
- computeActionFromQValues
- getQValue
- getAction
- update
Instance variables you have access to
- self.epsilon (exploration prob)
- self.alpha (learning rate)
- self.discount (discount rate)
Functions you should use
- self.getLegalActions(state)
which returns legal actions for a state
"""
def __init__(self, **args):
"You can initialize Q-values here..."
ReinforcementAgent.__init__(self, **args)
"*** YOUR CODE HERE ***"
self.qValues = util.Counter()
def getQValue(self, state, action):
"""
Returns Q(state,action)
Should return 0.0 if we have never seen a state
or the Q node value otherwise
"""
"*** YOUR CODE HERE ***"
return self.qValues[(state, action)]
util.raiseNotDefined()
def computeValueFromQValues(self, state):
"""
Returns max_action Q(state,action)
where the max is over legal actions. Note that if
there are no legal actions, which is the case at the
terminal state, you should return a value of 0.0.
"""
"*** YOUR CODE HERE ***"
actions = self.getLegalActions(state)
bestQvalue = -float('inf')
if not actions:
return 0.0
for action in actions:
if self.getQValue(state, action) > bestQvalue:
bestQvalue = self.getQValue(state, action)
return bestQvalue
# return max([self.getQValue(state, action) for action in actions])
util.raiseNotDefined()
def computeActionFromQValues(self, state):
"""
Compute the best action to take in a state. Note that if there
are no legal actions, which is the case at the terminal state,
you should return None.
"""
"*** YOUR CODE HERE ***"
actions = self.getLegalActions(state)
bestQvalue = self.computeValueFromQValues(state)
if not actions:
return None
bestActions = [action for action in actions if self.getQValue(state, action) == bestQvalue]
return random.choice(bestActions)
util.raiseNotDefined()
def getAction(self, state):
"""
Compute the action to take in the current state. With
probability self.epsilon, we should take a random action and
take the best policy action otherwise. Note that if there are
no legal actions, which is the case at the terminal state, you
should choose None as the action.
HINT: You might want to use util.flipCoin(prob)
HINT: To pick randomly from a list, use random.choice(list)
"""
# Pick Action
legalActions = self.getLegalActions(state)
action = None
"*** YOUR CODE HERE ***"
if not legalActions:
return None
if util.flipCoin(self.epsilon):
return random.choice(legalActions)
else:
return self.computeActionFromQValues(state)
util.raiseNotDefined()
def update(self, state, action, nextState, reward: float):
"""
The parent class calls this to observe a
state = action => nextState and reward transition.
You should do your Q-Value update here
NOTE: You should never call this function,
it will be called on your behalf
"""
"*** YOUR CODE HERE ***"
sample = reward + self.discount * self.computeValueFromQValues(nextState)
oldQ = self.getQValue(state, action)
self.qValues[(state, action)] = (1 - self.alpha) * oldQ + self.alpha * sample
def getPolicy(self, state):
return self.computeActionFromQValues(state)
def getValue(self, state):
return self.computeValueFromQValues(state)- 其中在
computeValueFromQValues函数中带#号的一行为for循环以下的简便写法,我写的版本易读性有些差而且简洁性也不够强。 - 在初始化中,我们依旧选择
Counter作为我们的数据存储结构,因为其初始化值为0的特性,我们的Coding过程方便了许多。 - 在函数
update中,就是围绕着Q-Learning的核心公式展开的,这个公式可以回顾Note9中的详细介绍 - 函数
getAction中的util.flipCoin(p)的功能不要遗漏看一下,在util.py文件中给出了如下实现。实现非常简单,含义也很明了:用在getAction函数中的的判断语句含义就是有self.epsilon的概率进入if分支,有1 - self.epsilon的概率进入else分支。这也是在Note10中提及到的ε-Greedy Policies
def flipCoin(p):
r = random.random()
return r < pQ4.Epsilon Greedy
Q4问题在Q3中已经实现了,没看清要求。正是上面刚刚提到的ε-Greedy Policies,原文档中也讲解了一下util.flipCoin(p)的具体逻辑。
You can simulate a binary variable with probability `p` of success by using `util.flipCoin(p)`, which returns `True` with probability `p` and `False` with probability `1-p`.原文档中还给了两段几乎相同的shell指令
python gridworld.py -a q -k 100 --noise 0.0 -e 0.1- 10% 随机探索
- 90% 走当前最优 Q
python gridworld.py -a q -k 100 --noise 0.0 -e 0.9- 90% 随机探索
- 只有 10% 走最优Q 可以很明显发现第一段shell运行的时候,智能体在探索到Reward最高的道路时,就基本一直重复走相同路线。而第二段智能体则基本一直在无规则运动
Q5.Q-Learning and Pacman
上面的代码可以直接通过Q5的autograder。需要理解并回顾一下的是,mediumGrid在用Q-Learning去学习是行不通的,因为其状态空间巨大,Q-Learning并不具备泛化能力.智能体意识不到遇到ghost是坏事,智能体只能记住在某个具体board下撞鬼是坏事
Q6.Approximate Q-Learning
Q6所呈现的Approximate Q-Learning就具备的泛化能力,智能体能够学习经验而不是学习特定的情况下该做出什么特定的行动。这个问题并不难,文档里也提供了可能需要的函数的定义。
我们可以发现,Approximate Q-Learning的总表达式,启发式的表达式和评估函数的表达式是有点类似的,在Proj1中的Q6.遍历角落问题的启发式有着启发式的具体实现,在Proj2中Q1.Reflex Agent的,也可以回顾一下观察三者的形式,他们都有着共同的思想
- Approximate Q-Learning表达式
- 启发式表达式
- 评估函数表达式
代码实现
class ApproximateQAgent(PacmanQAgent):
"""
ApproximateQLearningAgent
You should only have to overwrite getQValue
and update. All other QLearningAgent functions
should work as is.
"""
def __init__(self, extractor='IdentityExtractor', **args):
self.featExtractor = util.lookup(extractor, globals())()
PacmanQAgent.__init__(self, **args)
self.weights = util.Counter()
def getWeights(self):
return self.weights
def getQValue(self, state, action):
"""
Should return Q(state,action) = w * featureVector
where * is the dotProduct operator
"""
"*** YOUR CODE HERE ***"
features = self.featExtractor.getFeatures(state, action)
qValue = 0.0
for f in features:
qValue += self.weights[f] * features[f]
return qValue
util.raiseNotDefined()
def update(self, state, action, nextState, reward: float):
"""
Should update your weights based on transition
"""
"*** YOUR CODE HERE ***"
features = self.featExtractor.getFeatures(state, action)
currentQ = self.getQValue(state, action)
nextValue = self.computeValueFromQValues(nextState)
difference = (reward + self.discount * nextValue) - currentQ
for f in features:
self.weights[f] += self.alpha * difference * features[f]
def final(self, state):
"""Called at the end of each game."""
# call the super-class final method
PacmanQAgent.final(self, state)
# did we finish training?
if self.episodesSoFar == self.numTraining:
# you might want to print your weights here for debugging
"*** YOUR CODE HERE ***"
pass其中FeatureExtractor类中的getFeatures函数定义如下
class FeatureExtractor:
def getFeatures(self, state, action):
"""
Returns a dict from features to counts
Usually, the count will just be 1.0 for
indicator functions.
"""
util.raiseNotDefined()整体实现并没有什么难点,只是需要对着公式用代码复刻一遍就好