Q1.Reflex Agent
Proj2的开头是一个完成评估函数的问题,评估函数的思想非常类似与启发式的思想。相较与Proj1不同的是,该过程添加了对抗智能体,还有ScaredTime的设定。完成评估函数的时候首先考虑就是评估函数的组成要素,其中可以大致表示为
总分 = 游戏自带分数 + 食物相关奖励 + scared鬼奖励 - stop惩罚 - 危险鬼惩罚原评估函数在Reflex Agent类中的scoreEvaluationFunction中实现,其只是返回了当前状态的分数,缺少很多必要的组成元素,可以用下列指令在shell中运行原评估函数的gui版本
python pacman.py -p ReflexAgent -l testClassic很容易发现的是,pacman在许多情况下采取了action集中的stop动作。这种行为及其拉低效率,所以把当采取stop这一步的影响也要算入评估函数的表达式中
代码实现
def evaluationFunction(self, currentGameState: GameState, action):
"""
Design a better evaluation function here.
The evaluation function takes in the current and proposed successor
GameStates (pacman.py) and returns a number, where higher numbers are better.
The code below extracts some useful information from the state, like the
remaining food (newFood) and Pacman position after moving (newPos).
newScaredTimes holds the number of moves that each ghost will remain
scared because of Pacman having eaten a power pellet.
Print out these variables to see what you're getting, then combine them
to create a masterful evaluation function.
"""
# Useful information you can extract from a GameState (pacman.py)
successorGameState = currentGameState.generatePacmanSuccessor(action)
newPos = successorGameState.getPacmanPosition()
newFood = successorGameState.getFood()
newGhostStates = successorGameState.getGhostStates()
newScaredTimes = [ghostState.scaredTimer for ghostState in newGhostStates]
"*** YOUR CODE HERE ***"
# print("Action: ", action)
# print("Pacman's position: ", newPos)
# print("Food count: ", newFood.count())
# print("Ghost positions: ", [g.getPosition() for g in newGhostStates])
# print("Scared times: ", newScaredTimes)
# print("-" * 30)
score = successorGameState.getScore()
if action == Directions.STOP:
score -= 10
foodList = newFood.asList()
if foodList:
minFoodDist = min(manhattanDistance(newPos, food) for food in foodList)
score += 10.0/minFoodDist
for ghostState in newGhostStates:
ghostPos = ghostState.getPosition()
dist = manhattanDistance(ghostPos, newPos)
if ghostState.scaredTimer > 0:
if dist > 0:
score += 5.0/dist
else:
if dist <= 1:
score -= 200
else:
score -= 5.0/dist
return score在Q1原文的提示中提及到了尝试数值的倒数而不是数值本身,在本阶段的代码实现也有体现
Note: As features, try the reciprocal of important values (such as distance to food) rather than just the values themselves.最终结果
Record: Win, Win, Win, Win, Win, Win, Win, Win, Win, Win
*** PASS: test_cases/q1/grade-agent.test (4 of 4 points)
*** 1278.3 average score (2 of 2 points)
*** Grading scheme:
*** < 500: 0 points
*** >= 500: 1 points
*** >= 1000: 2 points
*** 10 games not timed out (0 of 0 points)
*** Grading scheme:
*** < 10: fail
*** >= 10: 0 points
*** 10 wins (2 of 2 points)
*** Grading scheme:
*** < 1: fail
*** >= 1: 0 points
*** >= 5: 1 points
*** >= 10: 2 points
### Question q1: 4/4 ###
Finished at 20:20:52
Provisional grades
==================
Question q1: 4/4
------------------
Total: 4/4
在Q1测试中是可以完美拿到满分的,但是我运行了shell指令更换其他的大型复杂layout,发现智能体在后期很容易出现反复踱步的问题。经过AI的详细解答后总结原因得知,决策规则里有一行关键代码影响了智能体的行动决策过程
chosenIndex = random.choice(bestIndices)到后期之后,食物减少的同时鬼的距离也变远,两个方向的1/distance几乎一样,而且ghost的距离也差不多,总体来说多个action的分数会出现一样的情况。上述代码面对这种情况的时候会出现A → B → A → B的决策过程,掉入Note4中提及到的局部最优震荡陷阱,每一步都是最优,但整体状况上不前进。 从根源上讲,这和ReflexAgent天生没有长期记忆和规划能力有关系,缓解这个问题的解决方式可以是当检测到新位置和当前位置重复连续出现太多次,进行扣分操作
Q2.Minimax
首先可以回忆一下Note5中Minimax的伪代码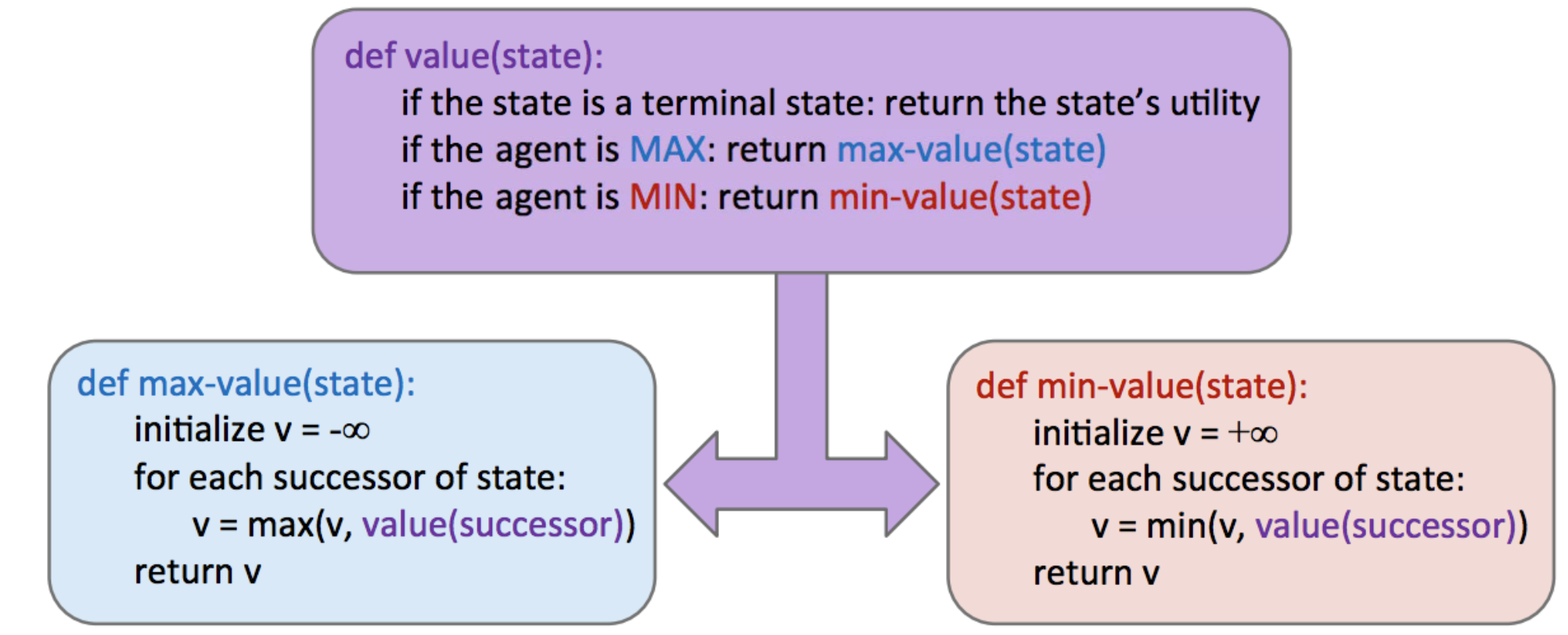 在实现文件中代码已经提供了可能用到的函数,非常全面。需要注意的是minimax树中的叶节点用
在实现文件中代码已经提供了可能用到的函数,非常全面。需要注意的是minimax树中的叶节点用self.evaluationFunction来评判状态分数
代码实现
class MinimaxAgent(MultiAgentSearchAgent):
"""
Your minimax agent (question 2)
"""
def getAction(self, gameState: GameState):
"""
Returns the minimax action from the current gameState using self.depth
and self.evaluationFunction.
Here are some method calls that might be useful when implementing minimax.
gameState.getLegalActions(agentIndex):
Returns a list of legal actions for an agent
agentIndex=0 means Pacman, ghosts are >= 1
gameState.generateSuccessor(agentIndex, action):
Returns the successor game state after an agent takes an action
gameState.getNumAgents():
Returns the total number of agents in the game
gameState.isWin():
Returns whether or not the game state is a winning state
gameState.isLose():
Returns whether or not the game state is a losing state
"""
"*** YOUR CODE HERE ***"
def minimax(state, agentIndex, depth):
if state.isWin() or state.isLose() or depth == self.depth:
return self.evaluationFunction(state)
numAgents = state.getNumAgents()
if agentIndex == 0:
value = -float('inf')
for action in state.getLegalActions(0):
successor = state.generateSuccessor(0, action)
value = max(value, minimax(successor, 1, depth))
return value
else:
value = float('inf')
nextAgentIndex = agentIndex + 1
for action in state.getLegalActions(agentIndex):
successor = state.generateSuccessor(agentIndex, action)
if nextAgentIndex == numAgents:
value = min(value, minimax(successor, 0, depth + 1))
else:
value = min(value, minimax(successor, nextAgentIndex, depth))
return value
bestScore = -float('inf')
bestAction = None
for action in gameState.getLegalActions():
successor = gameState.generateSuccessor(0, action)
score = minimax(successor, 1, 0)
if score > bestScore:
bestScore = score
bestAction = action
return bestAction这里一定要注意depth的逻辑,一次搜索是一次pacman和所有ghost的反应,即depth为2时涉及pacman和每个ghost移动两次
这里我想了一下代码具体运行过程才能想明白,假设self.depth是1,也就是pacman和ghost的移动次数都为1。最开始函数调用传入的minimax(successor, 1, 0),到运行到最后一个ghost智能体时,则会执行value = min(value, minimax(successor, 0, depth + 1)),再运行则会触发终止条件depth == self.depth,返回状态的分数return self.evaluationFunction()结束递归嵌套,所以说最终depth还是为1的
Q3.Alpha-Beta Pruning
依旧可以回忆一下Note5中Alpha-Beta Pruning的伪代码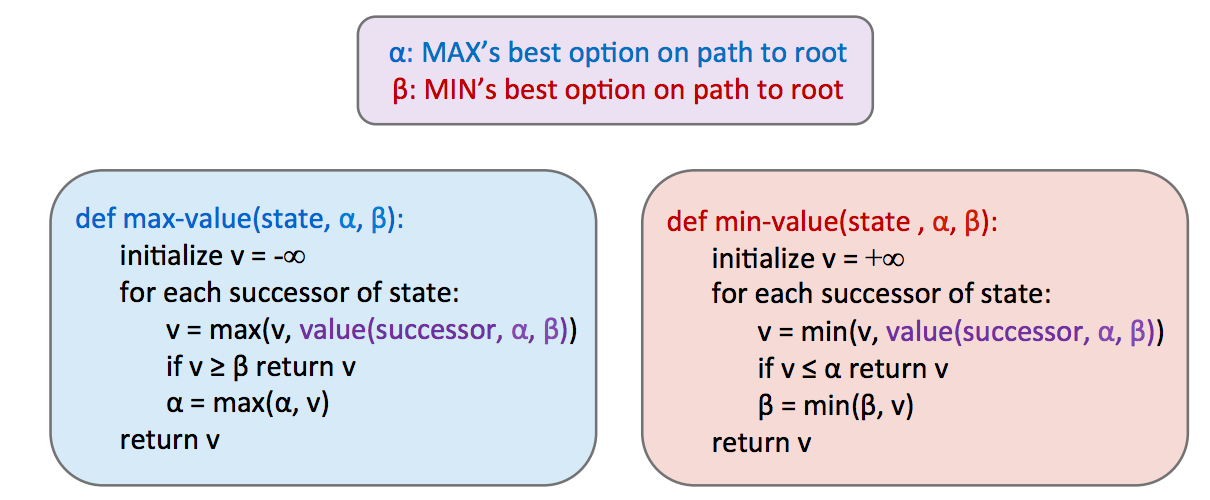
有个小细节需要注意的是,在Proj2的文档中,函数的判断条件稍微改了一下
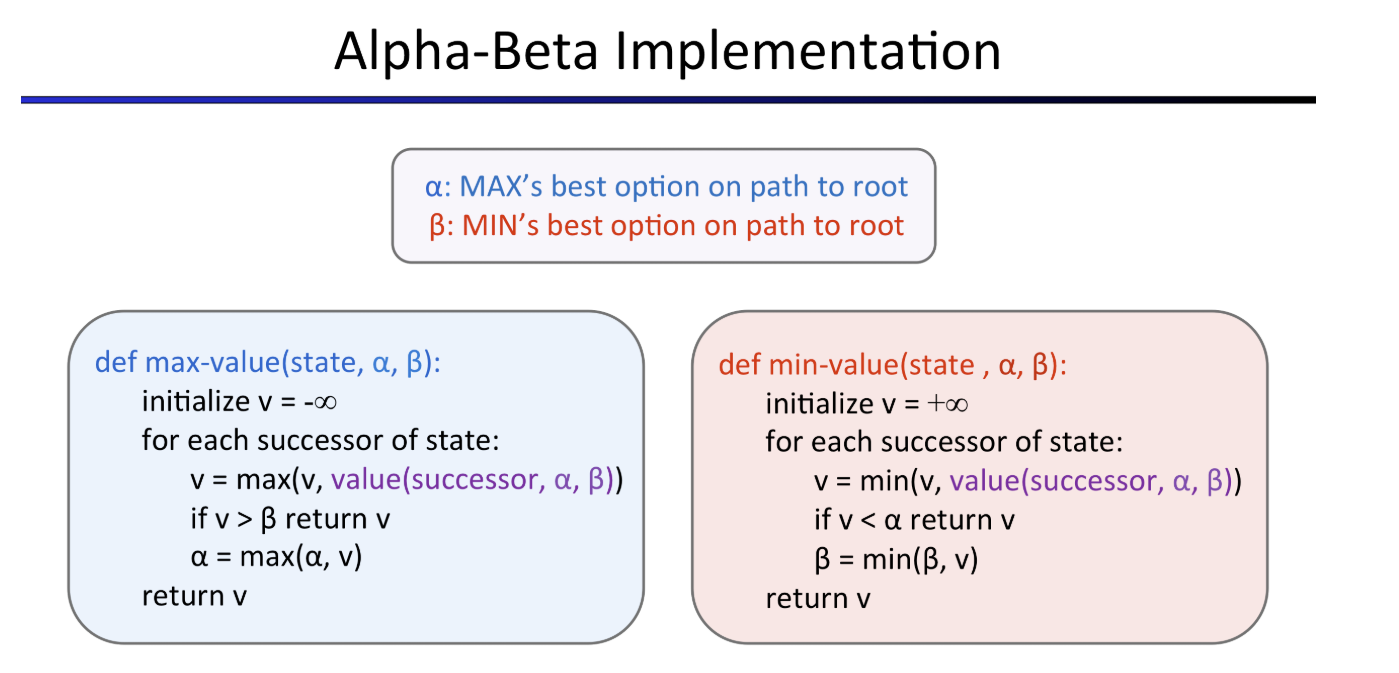 如果不按下面的伪代码实现的话,最后
如果不按下面的伪代码实现的话,最后autograder没法通过6-tied-root.test
*** FAIL: test_cases/q3/6-tied-root.test
*** Incorrect generated nodes for depth=3
*** Student generated nodes: A B max min1 min2
*** Correct generated nodes: A B C max min1 min2
*** Tree:
*** max
*** / \
*** min1 min2
*** | / \
*** A B C
*** 10 10 0代码实现
class AlphaBetaAgent(MultiAgentSearchAgent):
"""
Your minimax agent with alpha-beta pruning (question 3)
"""
def getAction(self, gameState: GameState):
"""
Returns the minimax action using self.depth and self.evaluationFunction
"""
"*** YOUR CODE HERE ***"
def alphabeta(state, alpha, beta, depth, agentIndex):
if state.isWin() or state.isLose() or depth == self.depth:
return self.evaluationFunction(state)
numAgents = state.getNumAgents()
if agentIndex == 0:
value = -float('inf')
for action in state.getLegalActions(0):
successor = state.generateSuccessor(0, action)
value = max(value, alphabeta(successor, alpha, beta, depth, 1))
if value > beta:
return value
alpha = max(alpha, value)
return value
else:
value = float('inf')
nextAgentIndex = agentIndex + 1
for action in state.getLegalActions(agentIndex):
successor = state.generateSuccessor(agentIndex, action)
if nextAgentIndex == numAgents:
value = min(value, alphabeta(successor, alpha, beta, depth + 1, 0))
else:
value = min(value, alphabeta(successor, alpha, beta, depth, nextAgentIndex))
if value < alpha:
return value
beta = min(beta, value)
return value
bestScore = -float('inf')
bestAction = None
alpha = -float('inf')
beta = float('inf')
for action in gameState.getLegalActions(0):
successor = gameState.generateSuccessor(0, action)
score = alphabeta(successor, alpha, beta, 0, 1)
if score > bestScore:
bestScore = score
bestAction = action
alpha = max(alpha, bestScore)
return bestAction代码实现的整体框架和Minimax基本没有差异,唯一需要注意的点就是根节点作为最大化节点也是需要剪枝的,所以说一定不能忘了倒数第二行的alpha = max(alpha, bestScore)
这里还需加强理解一下alpha和beta在各个阶段的具体数值才能深刻理解alpha-beta pruning的运行过程,拿下图来举个例子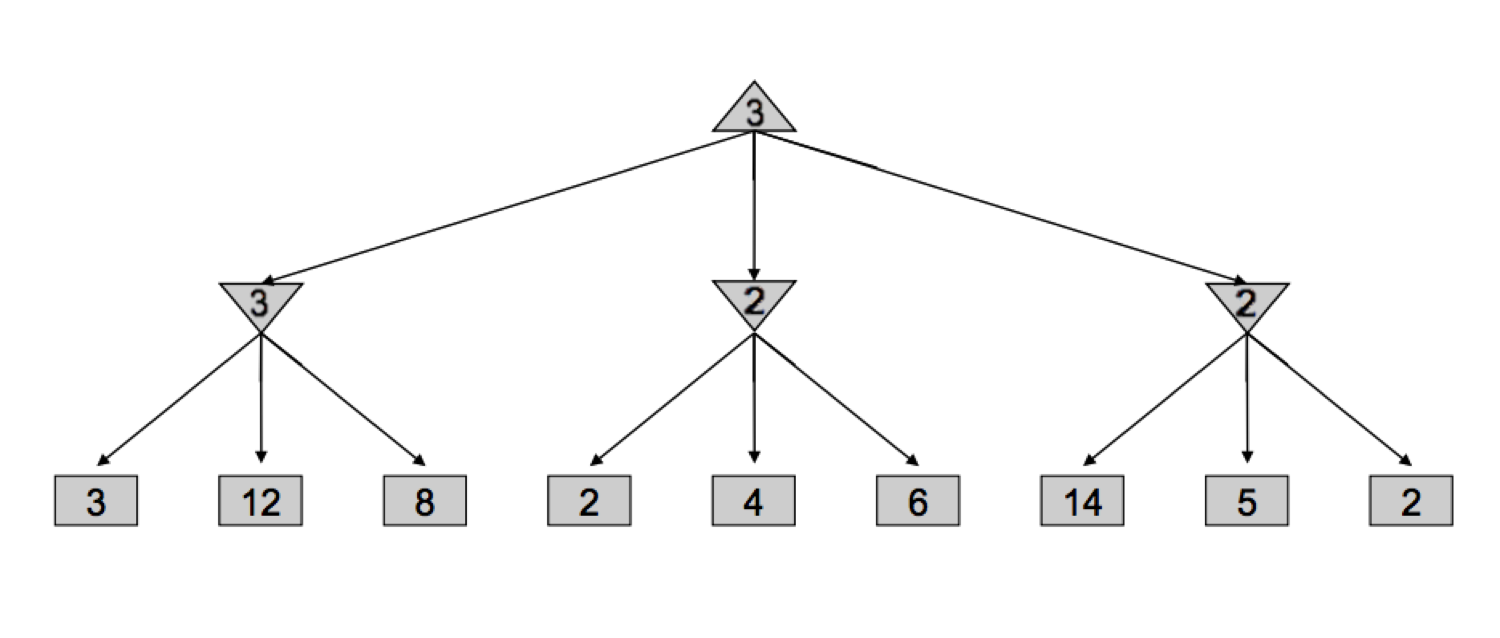
- 最开始根节点值为None,
alpha = -float('inf')且beta = float('inf') - 走最左子树,min1开始遍历自己的一个子节点(3),遍历过后更新min1的
beta = 3,之后遍历后两个子节点(12和6),得到min1的值 - 已知min1的值为3,根节点的alpha开始更新,执行
alpha = max(alpha, bestScore)语句,此刻根节点的alpha = 3 - 遍历中间子树,根节点alpha的值传了下来,当遍历到中间子树的第一个子节点(2),触发判断语句
value < alpha就直接退出此次遍历了
Q4.Expectimax
依旧依旧是可以回顾一下Note6中的伪代码
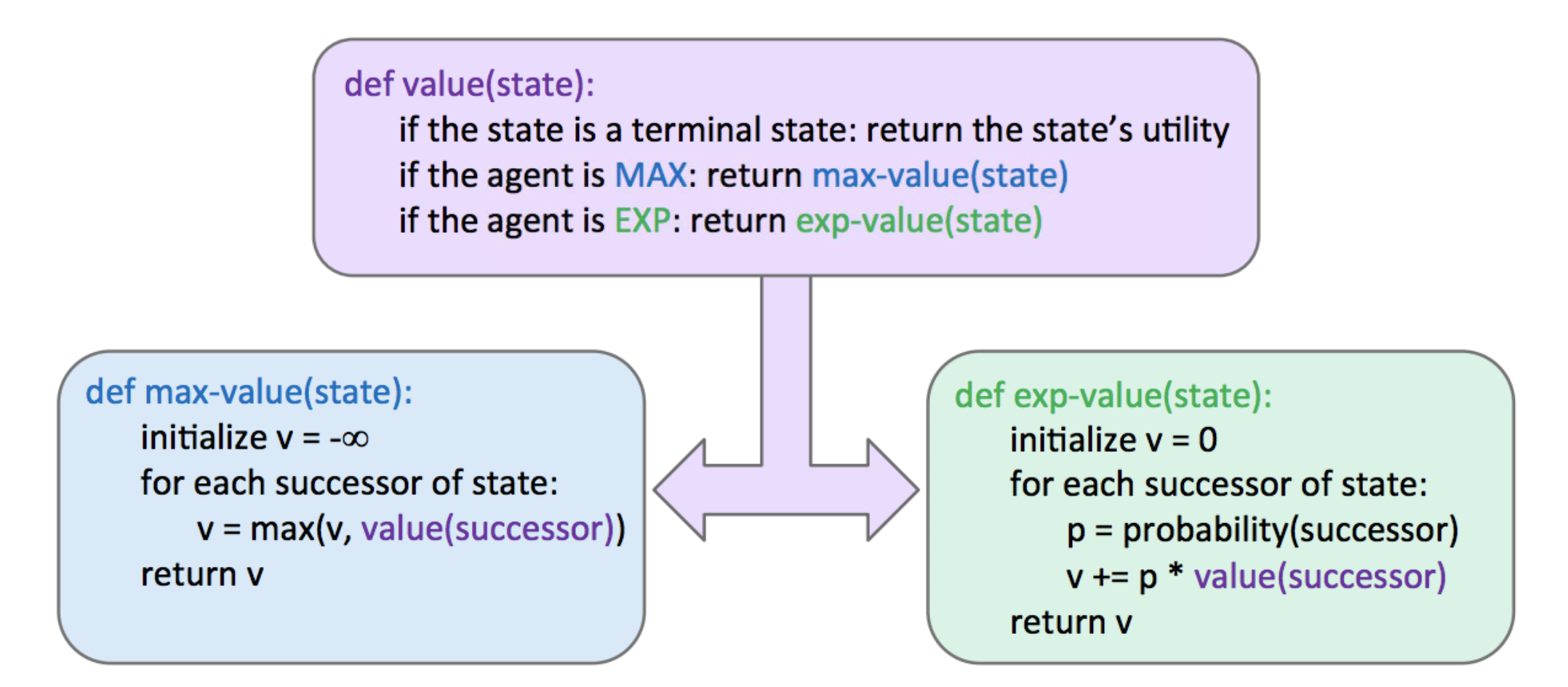
代码实现
class ExpectimaxAgent(MultiAgentSearchAgent):
"""
Your expectimax agent (question 4)
"""
def getAction(self, gameState: GameState):
"""
Returns the expectimax action using self.depth and self.evaluationFunction
All ghosts should be modeled as choosing uniformly at random from their
legal moves.
"""
"*** YOUR CODE HERE ***"
def expectimax(state, agentIndex, depth):
if state.isWin() or state.isLose() or depth == self.depth:
return self.evaluationFunction(state)
agentNum = state.getNumAgents()
if agentIndex == 0:
value = -float('inf')
for action in state.getLegalActions(0):
successor = state.generateSuccessor(0, action)
value = max(value, expectimax(successor, 1, depth))
else:
value = 0
actions = state.getLegalActions(agentIndex)
nextAgentIndex = agentIndex + 1
for action in state.getLegalActions(agentIndex):
successor = state.generateSuccessor(agentIndex, action)
probability = 1 / len(actions)
if nextAgentIndex == agentNum:
value += probability * expectimax(successor, 0, depth + 1)
else:
value += probability * expectimax(successor, nextAgentIndex, depth)
return value
bestAction = None
bestScore = -float('inf')
for action in gameState.getLegalActions(0):
successor = gameState.generateSuccessor(0, action)
score = expectimax(successor, 1, 0)
if score > bestScore:
bestScore = score
bestAction = action
return bestAction
util.raiseNotDefined()Q4这个问题和前面几个问题代码基本上都是一个模板,直接套就行
唯一需要注意的地方是有关probability的代码,对手将在getLegalActions中纯随机选择,所以probability的实现是probability = 1 / len(actions),原文档如下
To simplify your code, assume you will only be running against an adversary which chooses amongst their `getLegalActions` uniformly at random.原文档还提到了AlphaBetaAgent(以Minimax为基础)和ExpectimaxAgent的运行时候的区别
python pacman.py -p AlphaBetaAgent -l trappedClassic -a depth=3 -q -n 10python pacman.py -p ExpectimaxAgent -l trappedClassic -a depth=3 -q -n 10比较容易观察发现的现象是,ExpectimaxAgent可以在多局比赛中赢得几乎一半的数量,AlphaBetaAgent总是输。导致这个现象的根本原因就是在Note6开头中提及到的Minimax太过悲观,AlphaBetaAgent总是假设对手会采取最优行动,所以pacman会直接放弃争取机会。而Expectimax中认定ghost是随机行动,在计算期望值后,会在关键时刻决定赌一把
Q5.Evaluation Function
和Q1问题相同,都是完成Evaluation Function,函数传入的参数里面没有action,所以没有stop惩罚了,感觉没有了灵魂。我的整体思路是
总分 = 游戏自带分数 + 最近食物距离 - 食物数量(长期目标) - 普通鬼惩罚 + 可吃鬼奖励 - 胶囊距离惩罚代码实现```
def betterEvaluationFunction(currentGameState: GameState):
"""
Your extreme ghost-hunting, pellet-nabbing, food-gobbling, unstoppable
evaluation function (question 5).
DESCRIPTION: <write something here so we know what you did>
"""
"*** YOUR CODE HERE ***"
pos = currentGameState.getPacmanPosition()
food = currentGameState.getFood()
ghostStates = currentGameState.getGhostStates()
scaredTimes = [ghostState.scaredTimer for ghostState in ghostStates]
capsules = currentGameState.getCapsules()
score = currentGameState.getScore()
foodList = food.asList()
if foodList:
distToClosestFood = min(manhattanDistance(pos, food) for food in foodList)
score += 20.0 / distToClosestFood
else:
score += 1000
score -= 5 * len(foodList)
if capsules:
distToClosestCapsule = min(manhattanDistance(pos, capsule) for capsule in capsules)
score += 5.0 / distToClosestCapsule
score -= 20 * len(capsules)
for ghost in ghostStates:
ghostPos = ghost.getPosition()
ghostDist = manhattanDistance(pos, ghostPos)
if ghost.scaredTimer > 0:
score += 100.0 / ghostDist
else:
if ghostDist <= 1:
score -= 500
elif ghostDist <= 3:
score -= 200
elif ghostDist <= 5:
score -= 100
return score基本思路和Q1是一样的,没有了Stop的惩罚让pacman在执行动作过程中会出现特别特别多的无厘头停止动作,启发式内容仍需要优化,但是可以pass autograder )中,我们完全知道了转移函数和奖励函数