# Game( 博弈 )
Game Formulation
- 初始状态
s0 Players(s):在状态 s 下哪个玩家行动Actions(s):可采取的动作集合Result(s,a):状态转移函数Terminal-test(s):是否到达终局Utility(s, player):终局的得分(或价值)
Game和Search的return value的区别
| Return value | |
|---|---|
| Normal Search | Comprehensive plan |
| Adversarial Search | A strategy, or policy, which simply recommends the best possible move given some configuration of our agent(s) and their adversaries |
Minimax
Pre-Defination
State value
- A state’s value is defined as the best possible outcome (utility) an agent can achieve from that state.
Terminal utility
- The value of a terminal state, called a terminal utility.
- 其总是一些确定的已知值和固有的game property
面对没有opponent的状态是max的定义如下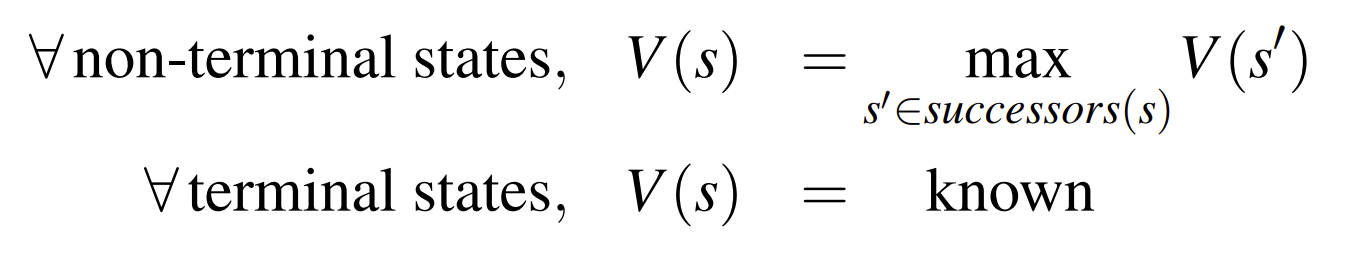
Defination
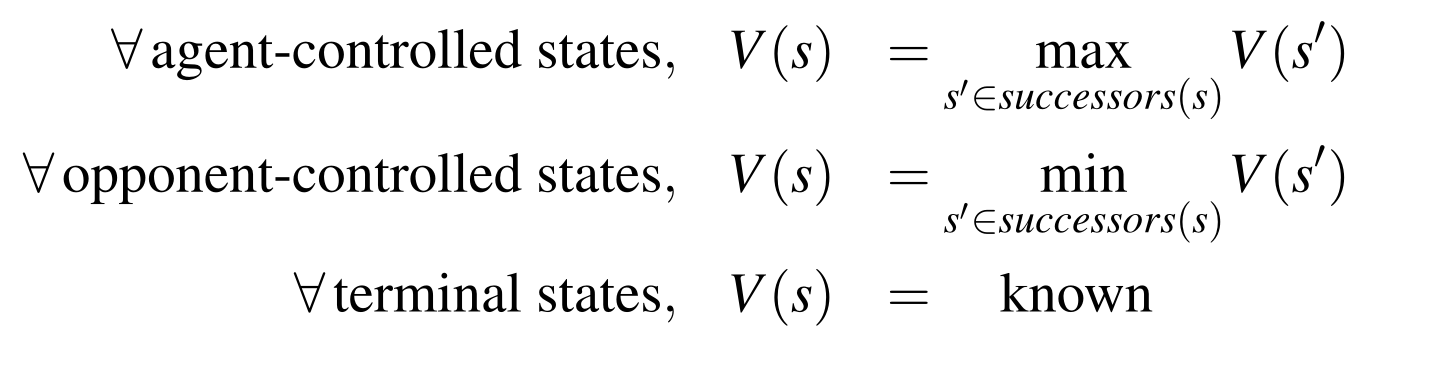
- 假设opponent总是采取对主体最坏的措施(即对手会选择让你获得收益最少的行为)。因此该算法就在你自己的回合最大化价值,对手在其回合最小化价值
- More precisely, it performs a postorder traversal(后续遍历) of the game tree. 必须知道所有的子节点,才处理节点本身,符合后续遍历的模式
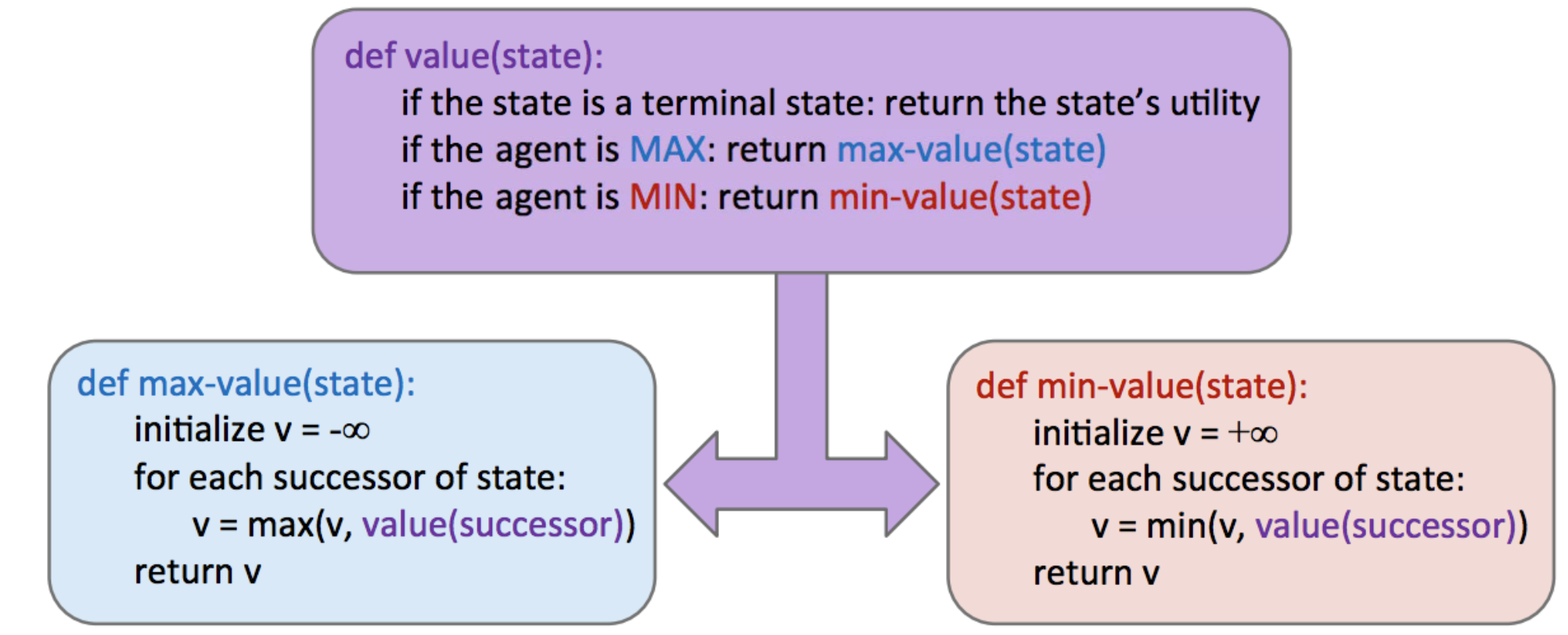
伪代码
Minimax Example
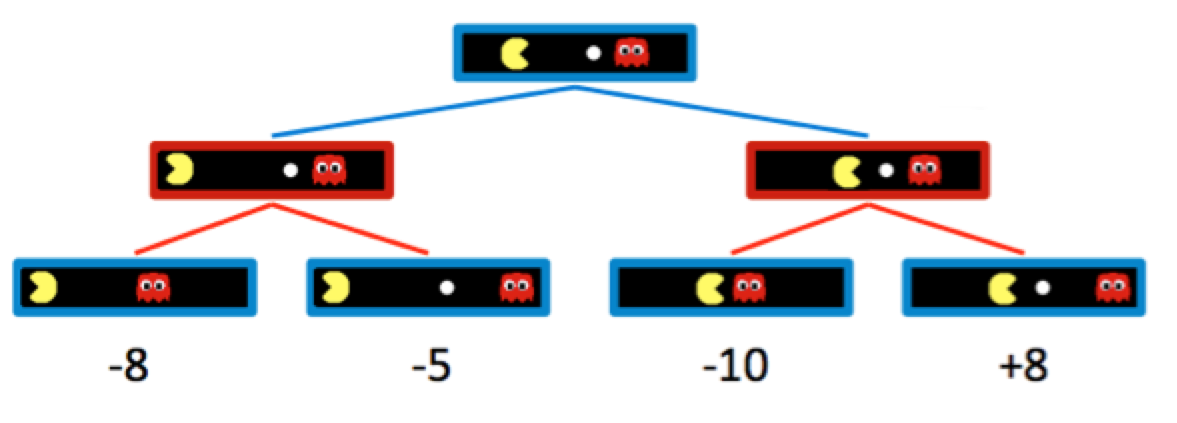
- The minimax algorithm only maximizes over the children of nodes controlled by Pacman, while minimizing over the children of nodes controlled by ghosts.
- Hence, the two ghost nodes above have values of min(−8,−5) = −8 and min(−10,+8) = −10 respectively.
- Correspondingly, the root node controlled by Pacman has a value of max(−8,−10) = −8. 通过Minimax算法,pacman会向左走来最大化他的分数。被迫对冲赌注,并违背直觉离开小球,最小化pacman的失败程度。—这是一个典型的behavior through computation #通过计算产生行为
Alpha-Beta Pruning
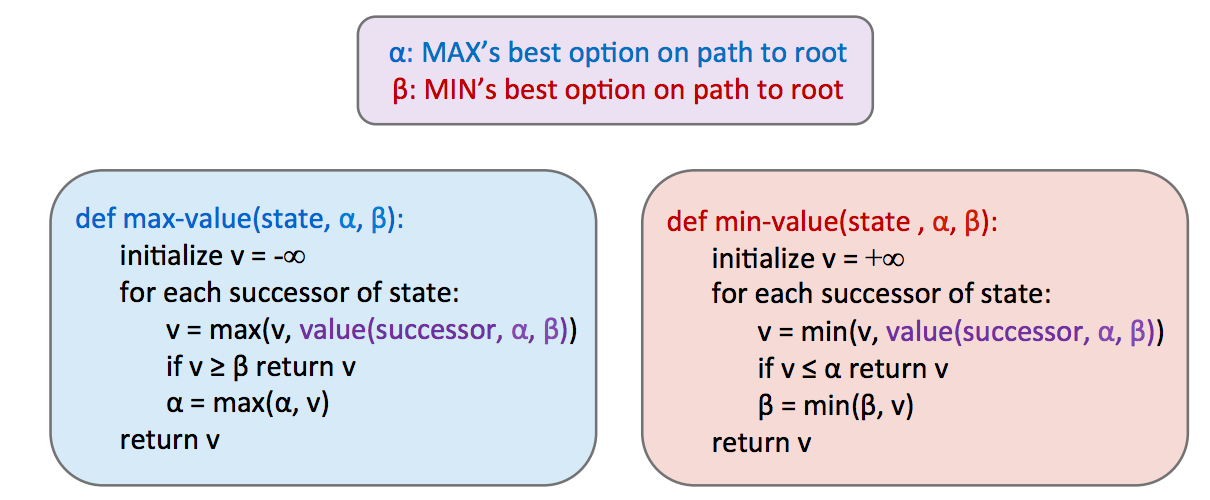
基于Minimax的算法时间复杂度过高为O(),其中b为分支因子m为可以找到终端节点的近似树深度。为了缓解这个问题,Minimax有一个优化方法 alpha-beta pruning
关键思想(剪枝条件)
- 在 max 节点处,若已有一个当前最好值
α,在考察某个子树时,如果子树的最优上界 ≤ α,就可以剪掉(因为父节点肯定不会选这个子树)。 - 在 min 节点处,则用
β(当前最小值);若子树最优下界 ≥ β,则剪掉。
Alpha-Beta Pruning Example
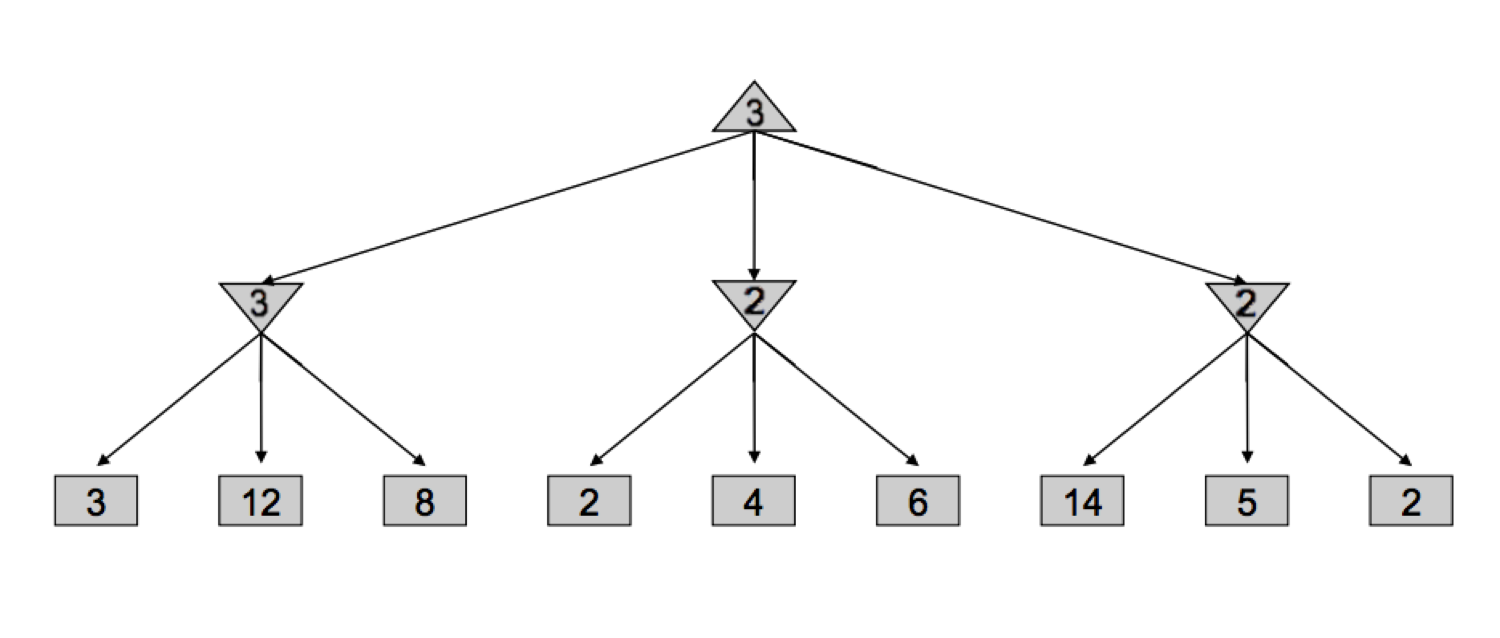
- Square nodes corresponding to terminal states
- Downward-pointing triangles corresponding to minimizing nodes
- Upward-pointing triangles corresponding to maximizer nodes
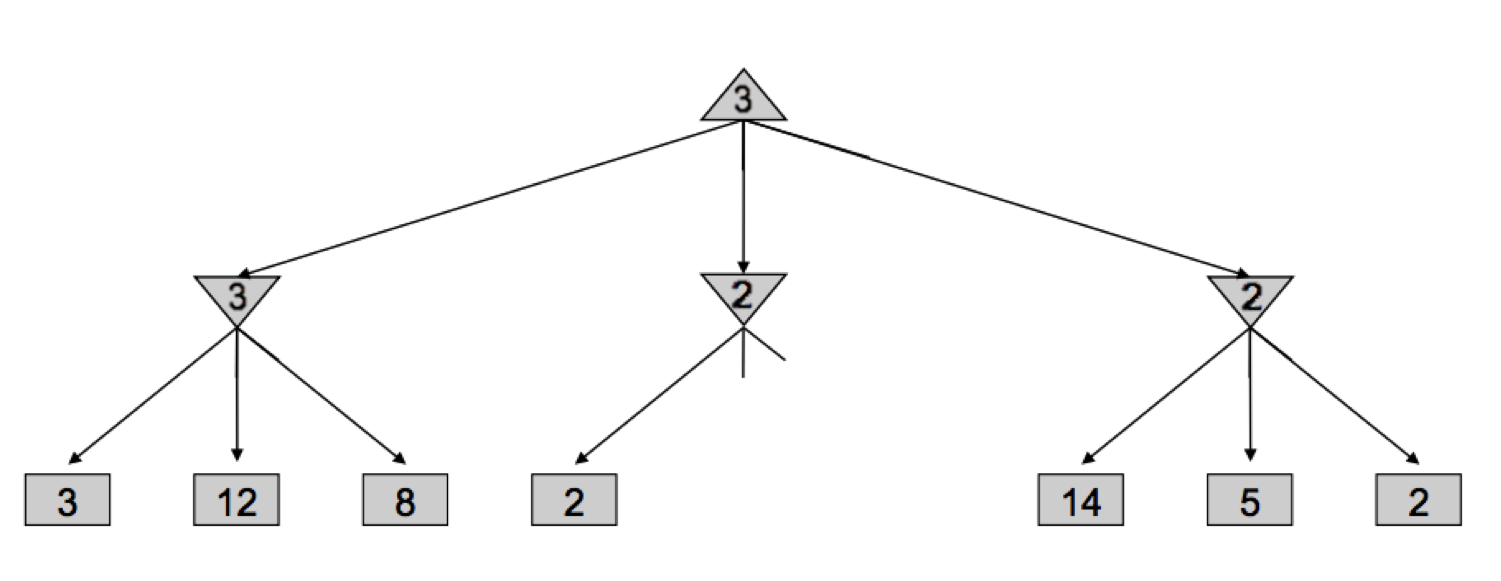
中间的minimizer当遇到第一个子节点,即值为2的节点,就可以知道minimizer的返回值是⇐2的。回看maxmizer,处理完第一个minimizer后,第一个minimizer的返回值为3。maxmizer就不会再取中间的minimizer的值,值为4和6的节点就可以被剪掉
伪代码实现
- 在理想情况下可以把时间复杂度降低到O(),最坏情况下依旧是O()
- 实践中,良好的move ordering(动作排序) 会让 alpha-beta 非常高效。
Evaluation Functions
尽管Alpha-Beta Pruning可以很好的帮助我们增加运行Minimax的深度,但对于大部分的game(博弈)来说,有时候不足以到达搜索树的底部。常用做法:搜索到一定深度后用评估函数估值(depth-limited minimax)
常见形式:线性组合(linear combination)
- Each corresponds to a feature extracted from the input state s, 是从局面提取的特征(如在跳棋游戏中子数、王子数、控制中心格子数、棋子位置安全度等)
- Each feature is assigned a corresponding weight (权重)
Evaluation Functions Example
符合跳棋游戏的一个Evaluation Function
- 设计要点:
- 选择能反映“好坏”的特征;好特征会在大多数情况下给“好局面”更高分。
- 权重需要调参:可以用自对弈或机器学习方法调整。
- 更深的搜索 + 同样的评估函数通常能得到更好的结果(因为误差被后续搜索缓和)。