Machine Learning
之前前面我们所涉及的概率模型章节里面,我们一直认为的概率表就是给定的条件。也就是说我们直接拿模型来推理,但没有讨论这个概率到底是怎么来的。现在我们进入了Machine Learning章节,也就是开始研究如何根据数据,构造模型或者学习模型参数。
Machine Learning分类
Supervised Learning
有输入也有对应的输出。这个过程目的就是为了学习input -> output的映射规律,然后预测新的数据。这门课里,这个Note19只讨论该类别。
Unsupervised Learning
只有输入没有标签。这个过程目的不是为了预测正确答案,而是为了发现数据内部结构。
数据集划分
 划分区别很简单:
划分区别很简单:
- Training set:用来学习参数
- Validation set:用来调参,选择模型
- Test set:用来最终评估泛化模型
Naive Bayes
Naive Bayes是一种用于分类的概率模型,它的核心思想是:给定一个样本的若干fearute,分别计算它属于每个类别的概率,然后选最大的那个类别。下面我们引入的例子,就是判断一封邮件是spam还是ham的概率。
Feature
我们把对象表示称一组特征,也就是features,因为机器学习模型一般不会直接拿原始对象来学习。
在这个例子中所谓的feature engineering就是看某个词有没有出现,某个词出现了多少次,是否全大写等等特征。特征选的好不好会很明显影响模型性能。
这个思想类似于我们很早之前在Note5提及到的Evaluation Functions的特征值
核心假设
我们在这里用f(x)表示对输入x做feature function之后得到的特征表示:
raw input x --f(x)--> feature representation假设有一个大小为n的词典,对于每一封邮件提取一个特征向量我们把第i个特征F_i当成一个bool值的随机变量。也就是说值为1就代表第i个词出现了,值为0则代表没有出现。如果第200个词为free并且F_200 = 1则代表这封邮件里面出现了free。
我们现在就能发现一个很直接的问题,就是如果我们直接建设一个完整的联合分布:
其中Y为类别标签,那么这个表的大小将会随着n指数级增长。大约会需要个表项,这绝对不是我们想要的数量级。这时候我们就引入了Naive Bayes的核心假设:
Features are conditionally independent given the class label.
这是Naive的真正来源,因为现实中很多特征其实并不独立,但是模型强行把它们看成独立的。
也就是下图的理解,在给定类别Y的条件下,各个特征彼此独立。在Note13的D-Separation算法中我们也提及到了判断每个是否条件独立的方法
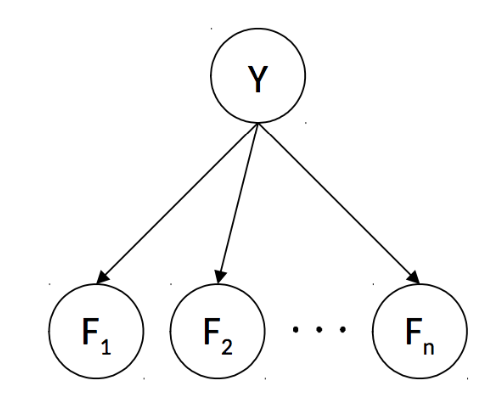
在数学上我们可以理解为下面的式子:
优点很明显:这个假设可以把原来指数级复杂的问题,压缩成线性规模的问题。原来需要存下整个联合表,但是我们现在只需要存一个P(Y)还有每个特征各自的P(F_i | Y),这很明显总表项数是和n线性相关的。
缺点更明显了:有很多本来就有关联的东西,再这个模型中强行被解析成为没有关联的事物。用计算上的简洁舍弃了相关性,忽略掉了精度。
Naive Bayes的预测公式
我们的目标就是在给定特征向量之后预测最有可能的类别
这里我们注意一下公式第一行到第二行的转换,因为是
并且我们要的是能让选后验概率最大的类别,转换后不会改变最后结果。 我们类比一下,如果不止两类,而是有k类,结果仍然一样:
Parameter Estimation
我们在上面讨论的模型结构是有了,但是还有一个关键问题就是:我们用的这些概率和从哪里来?这就引入我们的参数估计,我们引入的是最基础的方法Maximum Likelihood Estimation(MLE)
MLE的基本思想是:假设你有一批样本,你相信这些样本来自某个由参数θ控制的分布,问题是θ具体是多少?这和我们上面阐述的思想大差不差,就是选择让当前样本最有可能出现的参数值,即:
MLE的基本假设
MLE有三个基本假设:
- Identically Distributed:每个样本都来自同一个分布。比如掷同一枚硬币,每次正面概率都一样
- Conditionally Independent:给定参数后,样本彼此独立。
- Uniform Prior: 在看到数据之前,所有参数值都被看成等可能。 前两个合在一起就叫 independent, identically distributed(i.i.d.),第三个假设让MLE称为MAP(Maximum A Priori)的特例。
Likelihood
我们现在定义:对于固定的样本,likelihood是参数θ的函数:
如果满足i.i.d.,则:
我们希望找到一个θ,让这个函数L(θ)的值最大,我们就想到了一个方法:求导:
导数值为0的地方就是最大值或者最小值。我们去解求导后的方程就能知道θ的值
MLE Example
袋子里有两个红球一个蓝球,设红球概率为θ,蓝球概率就是1-θ Likelihood:
求导后并令导数为0求得θ = 2/3,和我们的直觉一致。因为3个球里面有2个红球
Maximum Likelihood For Naive Bayes
我们现在把MLE应用到Naive Bayes。还是先补充一下定义:
n:词典中的词数N:总训练样本数N_h:ham 邮件数量N_s:spam 邮件数量F_i:第 i 个词是否出现Y:标签,spam 或 ham- :第 j 个训练样本中,第 i 个特征的具体取值
学习P( = 1 | Y = ham)
该部分只推导下面的式子
也就是在ham邮件中,第i的词出现的概率是多少。因为在ham邮件里,第i个词只会有出现和不出现两种结果,所以我们的Likelihood公式写成如下形式:
注意我们的第二步转换部分,是一个经典的写法,数学小把戏: 如果的话
如果的话
我们又想到了,MLE的一个过程是求导啊,但是我们现在是很多项在连乘,直接求导很难。我们又想到了把原式取对数,因为最大化 等价于最大化 ,我们就进行原式的取对数
经过了及其复杂的推导后,我们把log-likelihood求导并让导数为0,最后得到的是:
这意味着:
的MLE,就是在所有的ham邮件中,词i出现的次数/ham邮件总数 也就是count/total,也就是频率估计
我们推导的这个结论理解一下,就是我们推导出来了如果一个词在100个ham邮件里面出现了23次,那么:
这说明在 Bernoulli Naive Bayes 里,学习参数并不复杂。
一旦你有标注好的训练集,很多概率本质上都是“数一数”:
- P(Y = ham) = ham 数量 / 总样本数
- P(Y = spam) = spam 数量 / 总样本数
- P(F_i = 1 | Y = ham) = ham 类中该词出现次数 / ham 总数
- P(F_i = 1 | Y = spam) = spam 类中该词出现次数 / spam 总数所以Naive Bayes训练速度很快,原因之一就是在这里
Smoothing
MLE的缺点不是很明显,就是MLE完全按照训练数据集数据计数。如果某个事件在训练集中一次都没有出现,那么它的概率就会被估计成0。这会带来一个很严重的问题,在Naive Bayes的预测中,我们要做概率连乘
只要其中有一项是0,整个乘积就都是0了,这种情况太极端了,这就是overfitting。
Overfitting
Overfitting指的是模型过度贴合训练数据中的偶然现象,导致对新数据泛化不好。 这里的例子非常典型,因为训练集恰好某词只在spam里出现,到测试集里面就会犯错。纯频率估计在样本有限的时候太激进了。
Laplace Smoothing
为了解决0概率问题,我们就引入了如题所示的方法。它整体的思路可以概括成假装每种结果都额外看到了k次:如果某个随机变量x有| X |种可能结果,那么MLE是:
那么Laplace Smoothing之后的是:
这样我们的概率就不再是0,而是一个非常小的值但非0,成功解决问题
Conditional版本的Laplace Smoothing
对于条件概率,我们直接给出公式:
本身是由原来不平滑的公式变换过来的
Laplace Smoothing两种特殊情况
- 当k=0时,这时候退化成普通的MLE,smoothing strength为0
- 当k→∞,这时候虚构的额外样本太多了,真实的数据集反而占比很小,导致模型忽略真实数据