Perceptron
Linear Classifiers
我们在上次的Note19中提及到了Naive Bayes中的提取feature的思想,我们在这里尝试把一个数据点的所有特征提取出来,提取成为一个向量的形式
f(x) = [f1(x), f2(x), ..., fn(x)]与之对应的,每个feature还有一个权重
w = [w1, w2, ..., wn]线性分类器的基本思想是利用特征的线性组合来进行分类,我们把这个值叫做激活值激活函数之前的值即activation。具体公式如下
我们来着重看一下这个值:
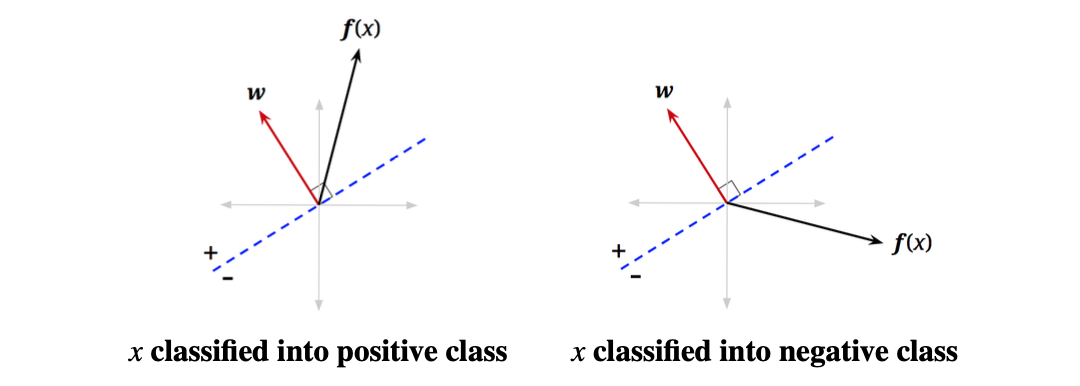
如果我们只有两个lable,可以回忆一下之前提及到的垃圾邮件的例子,这就是只有两个标签—只有ham和spam。
- 这时候如果为正,我们就把数据点标记为正类。
- 如果值为负,我们就把数据点标记为负类
Decision Boundary
我们用数学的角度来看一下的值:
看最后一串,决定值正负的是cosθ,因为两个向量的模是正的。也就是说
我们已知了向量w,那我们是不是可以画一条与向量w垂直的虚线,任何位于这条线上的特征向量其的值都为0,即满足式子,我们把这条线叫做决策边界即Decision Boundary
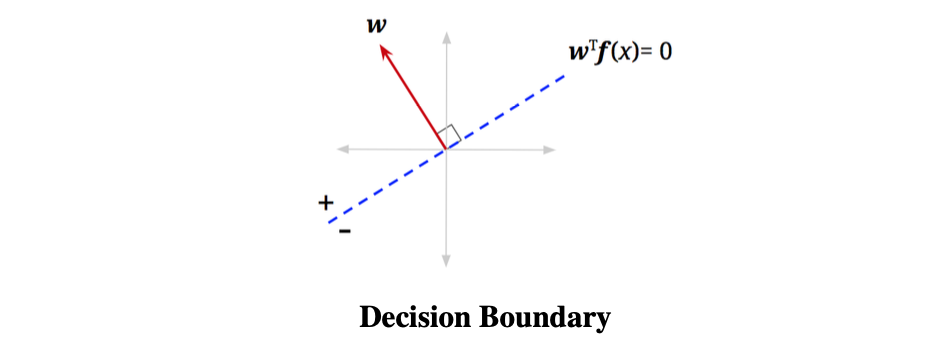 我们可以根据决策边界来判断的值
我们可以根据决策边界来判断的值
Binary Perceptron
二分类感知机是一个简单的线性分类器,它的目的是为了找到一个权重向量w让训练集中的样本都可以正确分类。
Perceptron Algorithm
1. Initialize weights: w = 0
2. For each training example (x, y*):
a. Compute prediction:
y = classify(x)
b. If y == y*, do nothing
c. If y != y*, update weights:
w ← w + y* f(x)
3. Repeat until all samples are classified correctly in one pass其中:
y*是真实的labley是模型预测的lablef(x)是样本特征向量
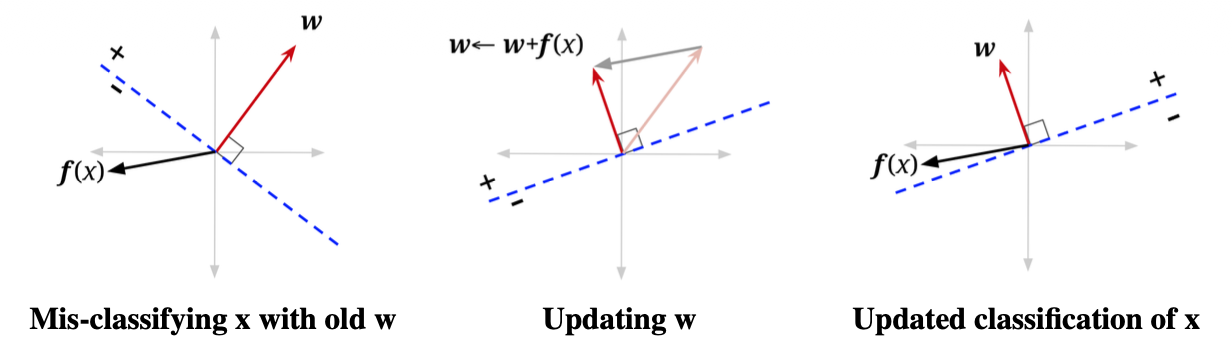
算法正确性验证
核心的更新规则就是 1.我们假设,。即原本为正类的数据点被分错分到负类里去了 2.我们可以推断的是:当前的是偏小的,我们期望是让变大 3.更新后的权重为
4.更新后的激活值为
5.因为
即激活值会变大,这也就表明了这种更新法则是符合我们的预期—让变大
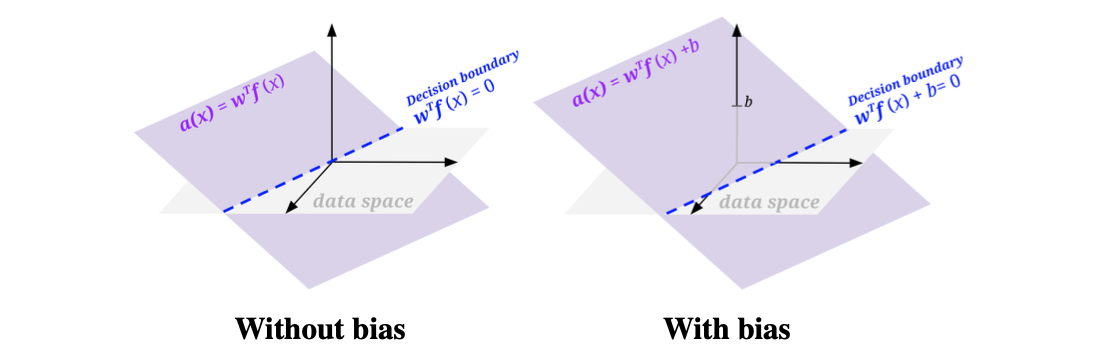
Bias
如果我们的决策边界模型只有,那么我们的决策边界就必须经过原点,这非常限制模型的能力,因为很多不同lable的数据点虽然能被一条直线分开,但那条直线不一定经过原点。我们就参考着一次函数的样式加入了bias term,让它变成
实现方法通常是给每个特征向量额外加一个恒等于1的feature,然后通过控制权重w来控制大小,这样模型仍然可以写成点积的形式:
Multiclass Perceptron
多个类别的和binary非常类似,如果有K个lable,那么就有K个权重。与二分类感知机对应的是,二分类感知机只有一个权重,因为可以用正负来区别两个lable.
对于输入样本,计算它的每个lable的score:
选择分数最高的lable:
多分类感知机更新规则
同样的:
y*是真实的并且正确的labley是被错误预测的lablef(x)是样本特征向量
那么就可以得到:
给正确类别的权重加上这个样本,给错误类别减去这个样本
Linear Regression
和前面不同的是:
Regression预测的是连续的数值,比如房价温度销量等等Classification预测的是类别 和前面相同的是:- 模型相同,即权重和特征向量的格式相同 特征向量是
对应的权重也是和之前的格式,注意特征向量的第一项1是bias term,那么我们可以得到为:
L2 Loss
训练线性回归时,我们希望预测值接近真实值
对于第 j 个样本:
L2 Loss是误差平方:
整个训练集上的loss:
前面加上1/2是为了求导时抵消平方项前面的2,让整体公式更加整洁
Matrix Form矩阵形式
将所有的训练样本堆起来:
设计矩阵:
权重为:
那么loss可以写成:
线性回归最重要的一个特点是它有闭式解( closed-form solution )
我们对loss求梯度:
令梯度为0:
如果可逆的话,那么就可以得到:
Logistic Regression
Logistic Regression用logistic function把线性模型输出转成概率,需要注意的是
Logistic Regression名字里有regression,但它主要用于classification
Logistic Function / Sigmoid Function
Logistic Function:
其中
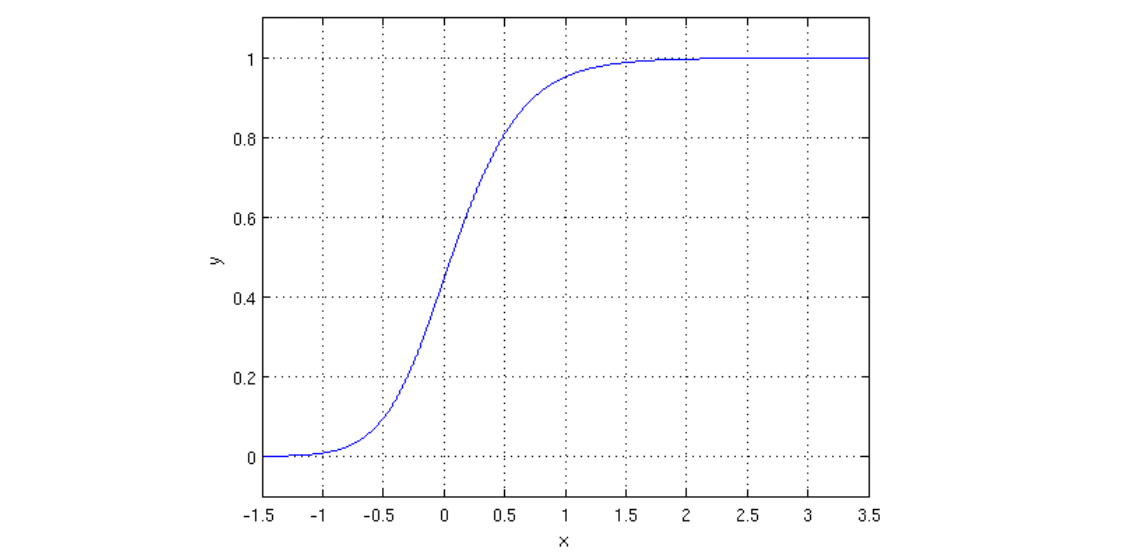 它的输出一定在0到1之间,因此可以解释为:
当时预测为正类,下面的式子为样本属于正类的概率
它的输出一定在0到1之间,因此可以解释为:
当时预测为正类,下面的式子为样本属于正类的概率
和当时预测为负类,下面的式子属于样本属于负类的概率
Logistic Regression的损失函数和梯度
首先有一个数学小性质
然后我们看L2 Loss的函数:
然后对第i个权重求偏导
因为logistic regression没有简单的closed-form solution, 所以通常用gradient descent来估计权重
Multi-Class Logistic Regression
和之前Perceptron的思路一样,都是从binary变成多类别的,对于多分类逻辑回归我们希望模型输出一个概率分布:
P(y=1|x), P(y=2|x), ..., P(y=K|x)
其中需要满足:
每个概率都 ≥ 0
所有概率加起来 = 1我们用的模型是Softmax Function,Softmax是logistic function的多分类拓展:
对于类别i我们有:
其中:
- 每个类别都有自己的权重向量
w_i; - 每个类别都会得到一个 score;
- 对 score 做指数变换;
- 再除以所有类别指数分数之和;
- 得到每个类别的概率
Likelihood
我们在这里用Likelihood方法来表示参数w以使观测到的数据有最大的可能性,我们的训练目标就是最大化这个likelihood:
注意一下区分:
Softmax负责算每个类别的概率;
Likelihood负责把每个样本“真实类别的概率”拿出来乘在一起
然后我们为了写出多分类的likelihood,定义下面:
即:
- 如果第
i个样本真实类别是k,那么t_{i,k}=1; - 否则
t_{i,k}=0这里举个例子更容易理解,对于某个样本x_i,Softmax会输出:
P(猫 | x_i)
P(狗 | x_i)
P(鸟 | x_i)但是真实标签只有一个,比如真实标签是狗,我们只想保留:
P(狗 | x_i)我们就用来表示:
如果第 i 个样本真实类别是 k,那么 t_{i,k} = 1
否则 t_{i,k} = 0所以就可以得到如果真实类别是狗,也就是第二类那么:
t_i = [0, 1, 0]所以说:
然后我们的likelihood公式就可以写成:
对应的log- likelihood就是: