Pytorch前置
这一次的Proj有很多调用了Pytorch,需要耗费一些时间补充一下前置知识:
Tensor
tensor是PyTorch里的数据容器,它可以是数组可以是列表可以是矩阵。下面是三个tensor变量的声明
tensor([2, 3])
tensor([[2, 3]])
tensor([
[2, 3],
[4, 5],
[6, 7]
])Dimension
这个表示tensor是几维,这个判断方法很简单,只需要看声明的tensor里的中括号是怎么配对的就可以,比如说tensor([2, 3])是一维向量的,tensor([[2, 3]])是二维矩阵
Shape
shape表示的是tensor的形状,可以简单理解成这个tensor有几行几列或者说有几层结构。
比如说
tensor([2, 3])它是一维的,里面有两个数字,所以说它的shape是(2, ),注意这个(2, )表示的意思就是这个tensor是一维的长度为2。
再看下面这个tensor
tensor([[2, 3]])它是二维的,可以看成一个表格
[
[2, 3]
]它有一行两列,所以说它的shape是(1, 2)
再比如下面的这个tensor:
tensor([
[1, 2],
[3, 4],
[5, 6]
])它是有三行两列,所以说shape是(3, 2)
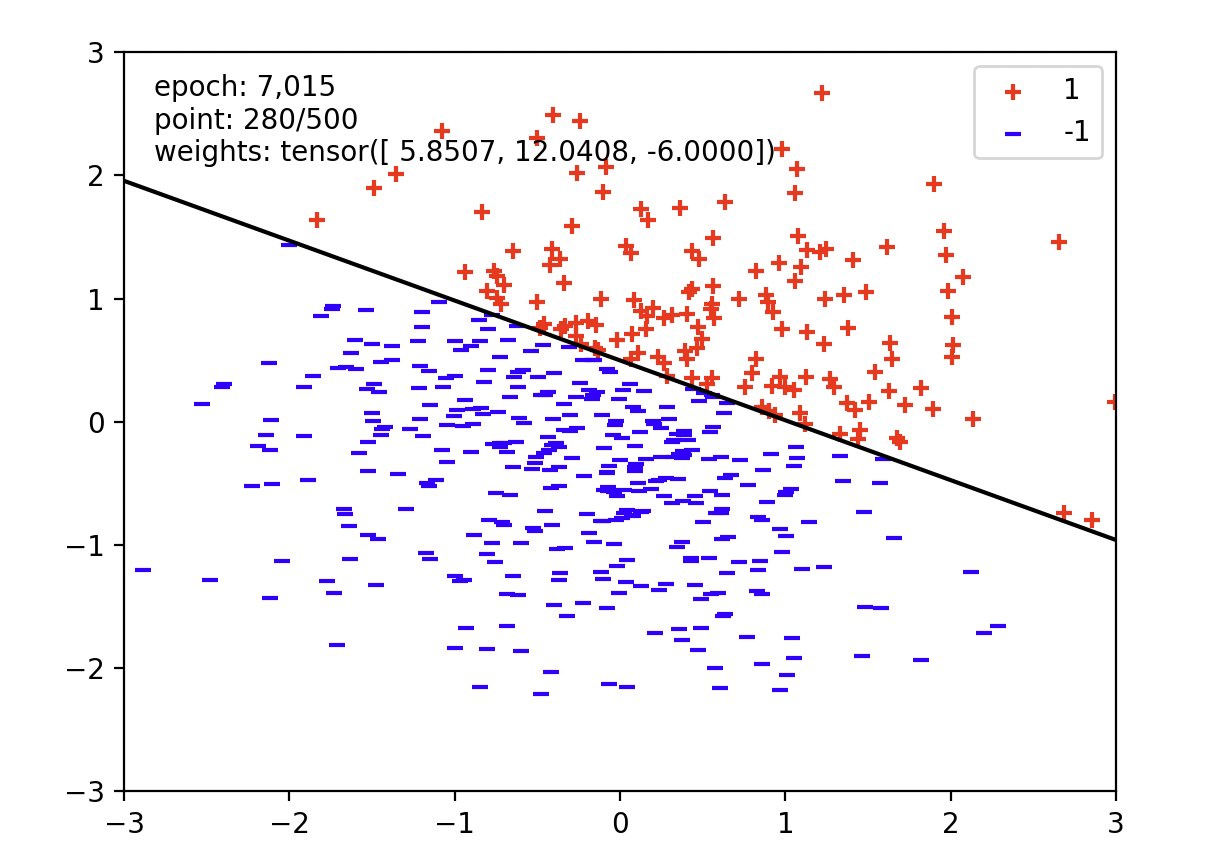
Q1.Perceptron Model
这个Question就是实现一个简单的Binary Classification.
但是PyTorch对于我这种0基础来说理解还是有一点难度,首先来解释一下为什么self.w的形状是(1, dimensions)其实这是autograder强行要求的,我最开始的思路是直接用一个一维向量,以一个[f1, f2...]的形式来表现出来。但是过不了autograder,这是因为PyTorch的常见形式是(batch_size, features),所以说x.shape = (1, dimensions)表明了这一批数据里有1个样本,每个样本有dimensions个特征。刻意改变一下就可以
其它的困难部分就只是函数了,第一次见一些函数可能不理解,ai问一下就好
代码实现
class PerceptronModel(Module):
def __init__(self, dimensions):
"""
Initialize a new Perceptron instance.
A perceptron classifies data points as either belonging to a particular
class (+1) or not (-1). `dimensions` is the dimensionality of the data.
For example, dimensions=2 would mean that the perceptron must classify
2D points.
In order for our autograder to detect your weight, initialize it as a
pytorch Parameter object as follows:
Parameter(weight_vector)
where weight_vector is a pytorch Tensor of dimension 'dimensions'
Hint: You can use ones(dim) to create a tensor of dimension dim.
"""
super(PerceptronModel, self).__init__()
"*** YOUR CODE HERE ***"
self.w = Parameter(ones(1, dimensions))
def get_weights(self):
"""
Return a Parameter instance with the current weights of the perceptron.
"""
return self.w
def run(self, x):
"""
Calculates the score assigned by the perceptron to a data point x.
Inputs:
x: a node with shape (1 x dimensions)
Returns: a node containing a single number (the score)
The pytorch function `tensordot` may be helpful here.
"""
"*** YOUR CODE HERE ***"
return torch.tensordot(x, self.w, dims=([1], [1]))
def get_prediction(self, x):
"""
Calculates the predicted class for a single data point `x`.
Returns: 1 or -1
"""
"*** YOUR CODE HERE ***"
score = self.run(x)
if score >= 0:
return 1
else:
return -1
def train(self, dataset):
"""
Train the perceptron until convergence.
You can iterate through DataLoader in order to
retrieve all the batches you need to train on.
Each sample in the dataloader is in the form {'x': features, 'label': label} where label
is the item we need to predict based off of its features.
"""
with no_grad():
dataloader = DataLoader(dataset, batch_size=1, shuffle=True)
"*** YOUR CODE HERE ***"
while True:
mistakes = 0
for batch in dataloader:
x = batch['x']
y = batch['label']
prediction = self.get_prediction(x)
true_lable = y.item()
if prediction != true_lable:
self.w += true_lable * x
mistakes += 1
if mistakes == 0:
breakLinear Regression Example
数据设置
我们了解一个用PyTorch进行最小的训练神经网络的例子,来了解整体的训练流程。 首先假设我们的真实原始公式是
所训练的模型在最开始并不知道真实参数为7, 8, 3,只能通过训练来慢慢迭代模型。模型假设自己有一个公式:
模型的任务就是通过训练找到合适的m0, m1, b
我们给定的训练样本是
x = torch.Tensor([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])
y = torch.Tensor([
[3],
[11],
[10],
[18]
])这里的y值表示的是每个样本对应的真实y值。我们输入的特征有两个,所以权重也有两个,分别对应每个特征。权重写成矩阵就是m = Tensor(2, 1),其中m的shape是m.shape = (2, 1),这是因为它的格式是:
[
[m0],
[m1]
]为什么是m.shape = (2, 1)应该去看本次PyTorch前置中的Shape定义
模型计算
我们的一个batch有4个样本,其中x的矩阵形式是这样:
x = torch.Tensor([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])x的shape就是x.shape = (4, 2),一共是4个样本,每个样本有两个特征。而权重m的形状是m.shape = (2, 1),所以说运算矩阵乘法x @ m,其形状变化为(4, 2) @ (2, 1) = (4, 1),也就是说模型会一次性得到4个预测值predicted_y.shape = (4, 1),这正好和真实答案y.shape = (4, 1)对得上
需要注意的是,如果不初始化,参数默认可能为0.这时候无论输入什么预测值都为0,这种情况下训练模型的效果将会变得毫无效果。
计算误差
我们计算误差使用的是MSE Loss模型,这个和我们在Note20中提及到的L2 Loss有点相似,但是多加了一步取平均值的操作:实际上就是均方误差
模型调整
在这里我们不过多强调实现细节,我们只需要知道optimizer帮助我们根据loss产生的梯度反向调整参数,这也是原Proj文档的本意,不需要深入理解。
代码流程
简单的训练流程就是下面四行代码:
optimizer.zero_grad()
loss = get_loss(...)
loss.backward()
optimizer.step()我们进行逐行解释,首先第一行:
optimizer.zero_grad()PyTorch默认会累积梯度,所以说每一轮训练之前我们要先进行清空梯度 第二行:
loss = get_loss(...)计算当前的Loss
第三行:
loss.backward()这一步是在进行反向传播,实际上就是在计算每个权重应该调整的方向
- 第四行:
optimizer.step()更新参数
Q2.Non-linear Regression
在这个神经元网络中,我们需要训练其接近定义域为[-2π, 2π]的sin(x)图像
这里还是需要补充一些前置知识和语法,要不然做起来纯有思路但是写不出来:
- 首先我们来看输入和输出的
shape,格式一般为(batch_size, input_features),其值都为(batch_size, 1) - 我们理解一下
Dataset,DataLoader,Batch,Sample的包含关系:Dataset里有很多个单个样本,DataLoader从Dataset里按batch_size取出一批样本,每一批样本就叫batch。 Linear(1, 256)表示的是线性层,这一层接收1个输入特征,输出256个新特征。这不是说凭空把1个数变成256个数,而是表示这一层有256个神经元,每个神经元都会看同一个输入x,但是每个神经元都有自己不同的权重和bias- 解释一下为什么
forward(self, x)函数里面最后一层没有加relu,这是因为sin(x)的结果是有负数的,如果最后加了relu负数会被强行变成0,模型就无法预测当x < 0的情况了,不符合输出的要求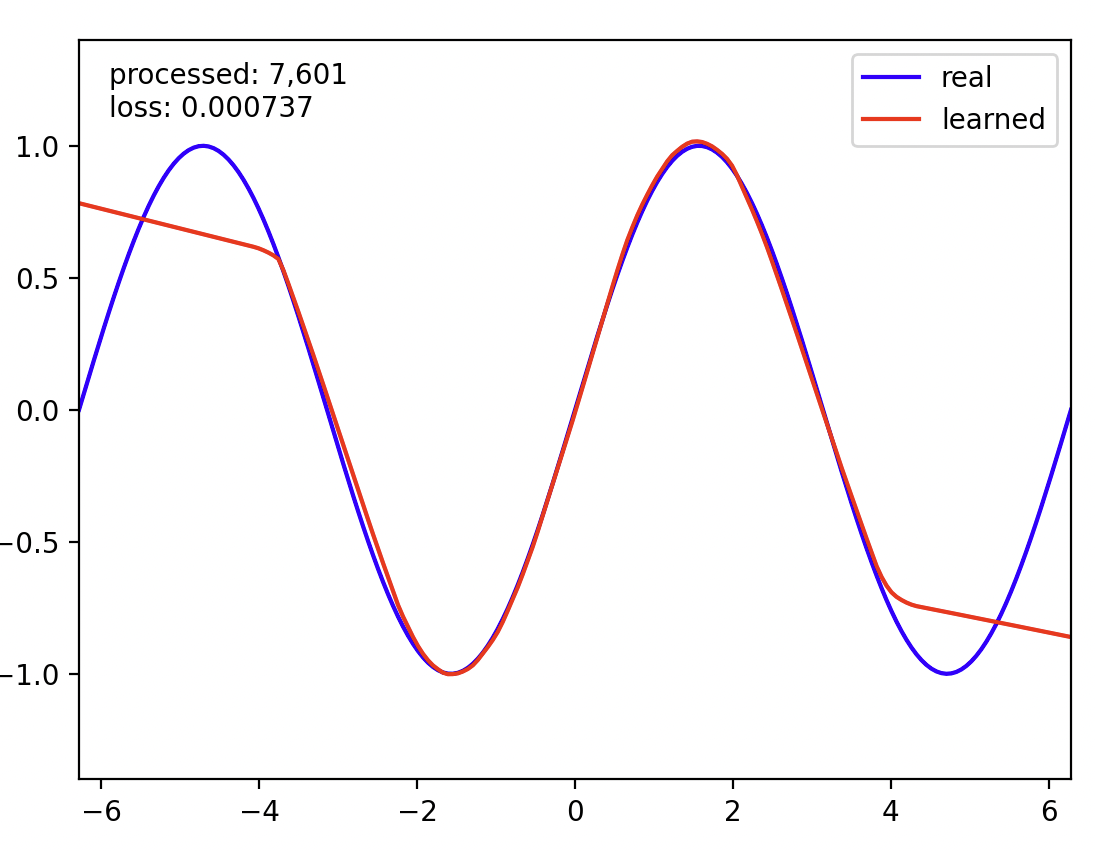
代码实现
class RegressionModel(Module):
"""
A neural network model for approximating a function that maps from real
numbers to real numbers. The network should be sufficiently large to be able
to approximate sin(x) on the interval [-2pi, 2pi] to reasonable precision.
"""
def __init__(self):
# Initialize your model parameters here
"*** YOUR CODE HERE ***"
super().__init__()
self.layer1 = Linear(1, 256)
self.layer2 = Linear(256, 256)
self.layer3 = Linear(256, 128)
self.output_layer = Linear(128, 1)
def forward(self, x):
"""
Runs the model for a batch of examples.
Inputs:
x: a node with shape (batch_size x 1)
Returns:
A node with shape (batch_size x 1) containing predicted y-values
"""
"*** YOUR CODE HERE ***"
x = relu(self.layer1(x))
x = relu(self.layer2(x))
x = relu(self.layer3(x))
x = self.output_layer(x)
return x
def get_loss(self, x, y):
"""
Computes the loss for a batch of examples.
Inputs:
x: a node with shape (batch_size x 1)
y: a node with shape (batch_size x 1), containing the true y-values
to be used for training
Returns: a tensor of size 1 containing the loss
"""
"*** YOUR CODE HERE ***"
predicted_y = self.forward(x)
loss = mse_loss(predicted_y, y)
return loss
def train(self, dataset):
"""
Trains the model.
In order to create batches, create a DataLoader object and pass in `dataset` as well as your required
batch size. You can look at PerceptronModel as a guideline for how you should implement the DataLoader
Each sample in the dataloader object will be in the form {'x': features, 'label': label} where label
is the item we need to predict based off of its features.
Inputs:
dataset: a PyTorch dataset object containing data to be trained on
"""
"*** YOUR CODE HERE ***"
dataloader = DataLoader(dataset, batch_size = 64, shuffle = True)
optimizer = optim.Adam(self.parameters(), lr = 0.001)
max_epochs = 2000
for epoch in range(max_epochs):
total_loss = 0
for batch in dataloader:
x = batch['x']
y = batch['label']
optimizer.zero_grad()
loss = self.get_loss(x, y)
loss.backward()
optimizer.step()
total_loss += loss.item()
average_loss = total_loss / len(dataloader)
if average_loss < 0.01:
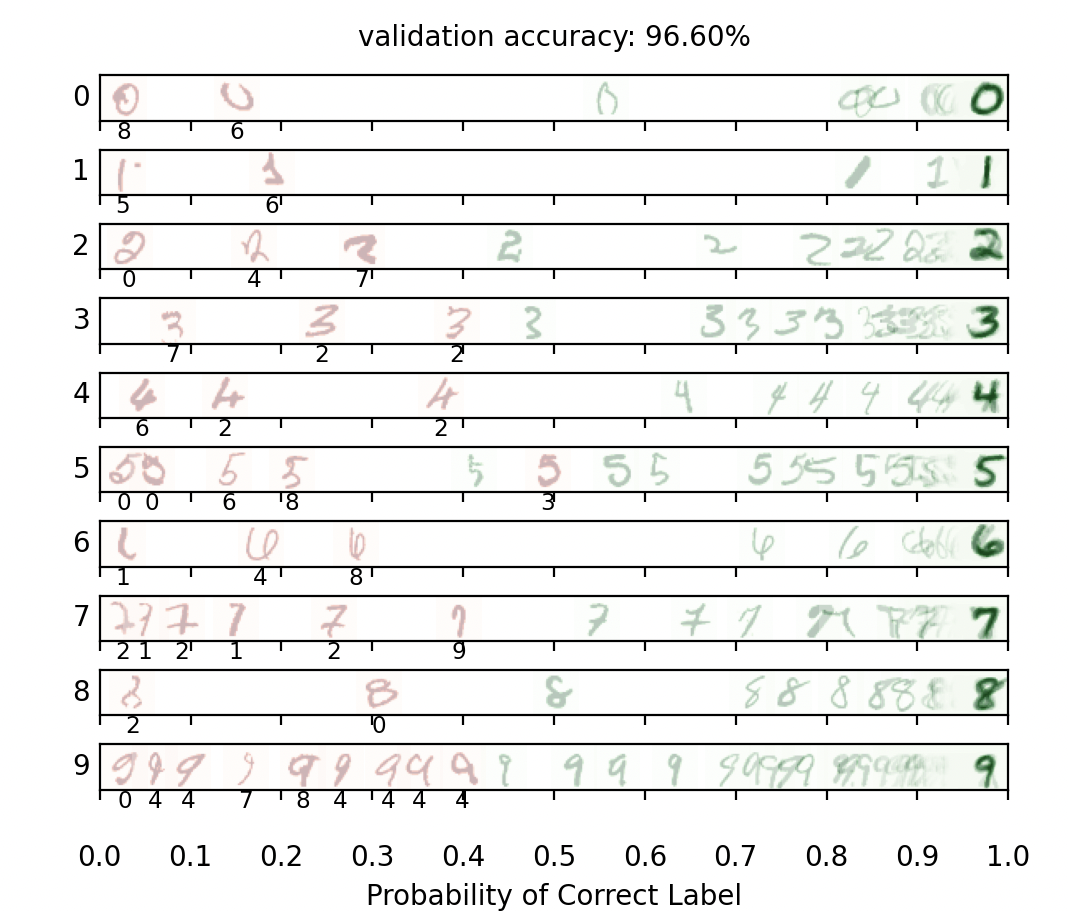
breakQ3.Digit Classification
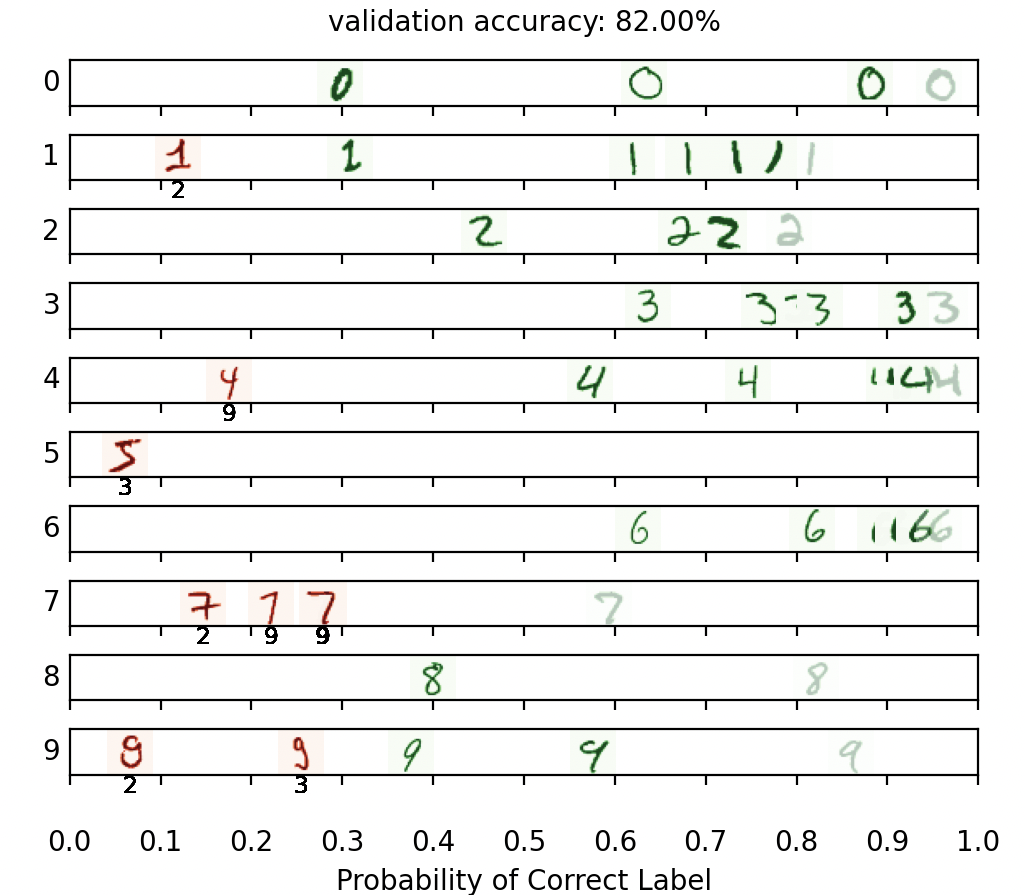
在这个神经元网络中,我们会训练模型来对MNIST数据集的手写数字进行分类:
Q3就属于是Classification问题了,不再是Regression问题。整体思路和上一个Q2思路一模一样,就是在套模版:
- 依旧先看输入输出的
shape,每张图片原本是28 × 28 像素,但是题目把所有像素点拉成了一个向量,所以单个样本的输入shape为x.shape = (784, ),单个样本的输出为output.shape = (1, 10) - 需要注意的一点就是我们在
run(self, x)函数里最后一层输出的时候依然不可以套relu,这是因为输出的是logits,它的格式为[0.2, -1.5, 3.8, 0.6, -0.7, 1.2, 0.1, 5.9, -0.4, 0.3],这10个位置分别代表数字0, 1, 2, 3, 4, 5, 6, 7, 8, 9的可能性。使用relu会让负数截断成0,影响分类效果
代码实现
class DigitClassificationModel(Module):
"""
A model for handwritten digit classification using the MNIST dataset.
Each handwritten digit is a 28x28 pixel grayscale image, which is flattened
into a 784-dimensional vector for the purposes of this model. Each entry in
the vector is a floating point number between 0 and 1.
The goal is to sort each digit into one of 10 classes (number 0 through 9).
(See RegressionModel for more information about the APIs of different
methods here. We recommend that you implement the RegressionModel before
working on this part of the project.)
"""
def __init__(self):
# Initialize your model parameters here
super().__init__()
input_size = 28 * 28
output_size = 10
"*** YOUR CODE HERE ***"
self.layer1 = Linear(input_size, 256)
self.layer2 = Linear(256, 128)
self.output_layer = Linear(128, output_size)
def run(self, x):
"""
Runs the model for a batch of examples.
Your model should predict a node with shape (batch_size x 10),
containing scores. Higher scores correspond to greater probability of
the image belonging to a particular class.
Inputs:
x: a tensor with shape (batch_size x 784)
Output:
A node with shape (batch_size x 10) containing predicted scores
(also called logits)
"""
""" YOUR CODE HERE """
x = relu(self.layer1(x))
x = relu(self.layer2(x))
x = self.output_layer(x)
return x
def get_loss(self, x, y):
"""
Computes the loss for a batch of examples.
The correct labels `y` are represented as a tensor with shape
(batch_size x 10). Each row is a one-hot vector encoding the correct
digit class (0-9).
Inputs:
x: a node with shape (batch_size x 784)
y: a node with shape (batch_size x 10)
Returns: a loss tensor
"""
""" YOUR CODE HERE """
scores = self.run(x)
loss = cross_entropy(scores, y)
return loss
def train(self, dataset):
"""
Trains the model.
"""
""" YOUR CODE HERE """
dataloader = DataLoader(dataset, batch_size = 64, shuffle = True)
optimizer = optim.Adam(self.parameters(), lr = 0.001)
max_epochs = 10
for epoch in range(max_epochs):
for batch in dataloader:
x = batch['x']
y = batch['label']
optimizer.zero_grad()
loss = self.get_loss(x, y)
loss.backward()
optimizer.step()
validation_accuracy = dataset.get_validation_accuracy()
if validation_accuracy >= 0.98:
breakQ4.Language Identification
在这个神经元网络中,我们会训练模型来对语言进行识别并判断是五种语言中的哪一种:
这个问题和Q3一样,都属于Classification分类问题,但是有一定的理解难度:
- 我们依旧先来看输入输出的
shape:- 一个字符会被表示成一个47维的
one-hot向量,举一个例子,字母a是第0个字符,那么字母a会表示成[1, 0, 0, 0, ..., 0],单个字符的shape是(47, 0) - 假设一个单词的长度为
L, 单个单词的shape就是(L, 47) DataLoader提供的x原始shape为(batch_size, word_length, num_chars),也就是(batch_size, L, 47)- 题目中要求了我们用到
xs,其shape为(batch_size, 47),它是DataLoader提供的原x通过函数movedim()转换成的,其中xs[0]表示的是这一批单词的第一个字符,每一个xs[i]都表示这一批 64 个单词在第 i 个字符位置上的one-hot编码 - 输出要求每个语言的可能性,也就是输出的
shape为(5, )
- 一个字符会被表示成一个47维的
- 题目要求模型逐字符处理单词,因为不同长度不同,所以不能直接用固定长度,而是要用
RNN一步一步来读字符 - 在
run(self, xs)函数中才是关键实,- 第一个字符我们只用当前字符初始化
hidden state - 之后从第二个字符开始,每一步都结合两部分信息:一个是当前字符信息还有一个是之前读过的字符信息
整体难度还是有的,需要慢慢理解
shape的多变性和每一层的作用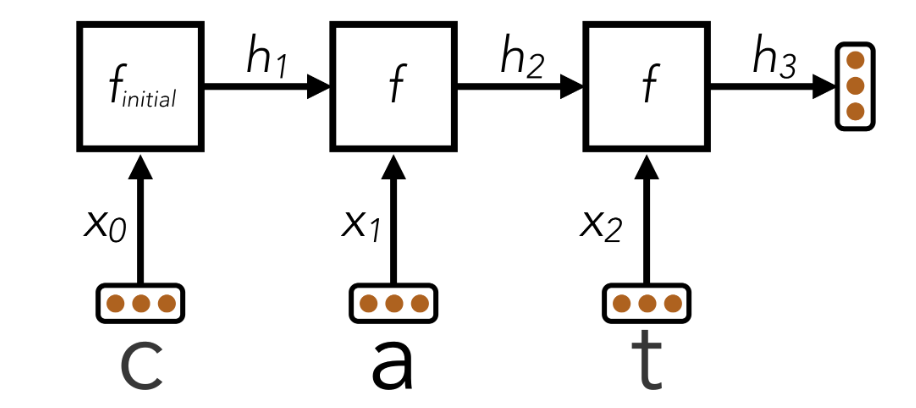
- 第一个字符我们只用当前字符初始化
代码实现
class LanguageIDModel(Module):
"""
A model for language identification at a single-word granularity.
(See RegressionModel for more information about the APIs of different
methods here. We recommend that you implement the RegressionModel before
working on this part of the project.)
"""
def __init__(self):
# Our dataset contains words from five different languages, and the
# combined alphabets of the five languages contain a total of 47 unique
# characters.
# You can refer to self.num_chars or len(self.languages) in your code
self.num_chars = 47
self.languages = ["English", "Spanish", "Finnish", "Dutch", "Polish"]
super(LanguageIDModel, self).__init__()
"*** YOUR CODE HERE ***"
self.hidden_size = 256
self.output_size = len(self.languages)
self.char_layer = Linear(self.num_chars, self.hidden_size)
self.hidden_layer = Linear(self.hidden_size, self.hidden_size)
self.middle_layer = Linear(self.hidden_size, self.hidden_size)
self.output_layer = Linear(self.hidden_size, self.output_size)
def run(self, xs):
"""
Runs the model for a batch of examples.
Although words have different lengths, our data processing guarantees
that within a single batch, all words will be of the same length (L).
Here `xs` will be a list of length L. Each element of `xs` will be a
tensor with shape (batch_size x self.num_chars), where every row in the
array is a one-hot vector encoding of a character. For example, if we
have a batch of 8 three-letter words where the last word is "cat", then
xs[1] will be a tensor that contains a 1 at position (7, 0). Here the
index 7 reflects the fact that "cat" is the last word in the batch, and
the index 0 reflects the fact that the letter "a" is the inital (0th)
letter of our combined alphabet for this task.
Your model should use a Recurrent Neural Network to summarize the list
`xs` into a single tensor of shape (batch_size x hidden_size), for your
choice of hidden_size. It should then calculate a tensor of shape
(batch_size x 5) containing scores, where higher scores correspond to
greater probability of the word originating from a particular language.
Inputs:
xs: a list with L elements (one per character), where each element
is a node with shape (batch_size x self.num_chars)
Returns:
A node with shape (batch_size x 5) containing predicted scores
(also called logits)
"""
"*** YOUR CODE HERE ***"
h = relu(self.char_layer(xs[0]))
for i in range(1, len(xs)):
char_part = self.char_layer(xs[i])
hidden_part = self.hidden_layer(h)
h = relu(char_part + hidden_part)
h = relu(self.middle_layer(h))
scores = self.output_layer(h)
return scores
def get_loss(self, xs, y):
"""
Computes the loss for a batch of examples.
The correct labels `y` are represented as a node with shape
(batch_size x 5). Each row is a one-hot vector encoding the correct
language.
Inputs:
xs: a list with L elements (one per character), where each element
is a node with shape (batch_size x self.num_chars)
y: a node with shape (batch_size x 5)
Returns: a loss node
"""
"*** YOUR CODE HERE ***"
scores = self.run(xs)
loss = cross_entropy(scores, y)
return loss
def train(self, dataset):
"""
Trains the model.
Note that when you iterate through dataloader, each batch will returned as its own vector in the form
(batch_size x length of word x self.num_chars). However, in order to run multiple samples at the same time,
get_loss() and run() expect each batch to be in the form (length of word x batch_size x self.num_chars), meaning
that you need to switch the first two dimensions of every batch. This can be done with the movedim() function
as follows:
movedim(input_vector, initial_dimension_position, final_dimension_position)
For more information, look at the pytorch documentation of torch.movedim()
"""
"*** YOUR CODE HERE ***"
dataloader = DataLoader(dataset, batch_size = 64, shuffle = True)
optimizer = optim.Adam(self.parameters(), lr = 0.001)
max_epochs = 25
for epoch in range(max_epochs):
for batch in dataloader:
x = batch['x']
y = batch['label']
xs = torch.movedim(x, 1, 0)
optimizer.zero_grad()
loss = self.get_loss(xs, y)
loss.backward()
optimizer.step()
validation_accuracy = dataset.get_validation_accuracy()
if validation_accuracy >= 0.87:
breakQ5.Convolutional Neural Networks
这个问题是让自己手搓一个2D的卷积函数,然后用卷积后的结果进行一个简单的数字分类:
首先来理解为什么需要卷积?我们在Q3中对于28 × 28像素点的处理方式是强行拉成一个一维向量。这种处理方式的弊端很明显,像素的上下左右位置都是有关联的,直接拉成向量会导致像素之间的关系丢失。
我们在这里所完成的函数convolve(input, weight)就是用一个2×2的weight矩阵,在input上从左到右从上到下滑动。每滑动一个位置就和input对应区域逐元素相乘,然后把乘积加起来,得到输出矩阵中的一个值。
我们在类DigitConvolutionalModel依旧是照着前面的模版来完成,可以复用前面的大部分代码
Example
比如我们的input是:
input =
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]卷积核:
weight =
[
[1, 0],
[0, 1]
]要求输出左上角第一个位置的时候,要取input左上角的2×2区域:
[
[1, 2],
[4, 5]
]然后和weight逐元素相乘:
1*1 + 2*0 + 4*0 + 5*1 = 6 输出左上角是6然后窗口往右滑一格:
[
[2, 3],
[5, 6]
]继续计算,直到滑完整个图。 需要注意的是,题目说这个题目不需要padding。padding的含义就是在图片外面补0,让卷积后大小不变。但是这个题目说明了不需要padding,所以卷积核不能滑出原图边界 一般公式为:
output_height = input_height - weight_height + 1
output_width = input_width - weight_width + 1代码实现
def Convolve(input: tensor, weight: tensor):
"""
Acts as a convolution layer by applying a 2d convolution with the given inputs and weights.
DO NOT import any pytorch methods to directly do this, the convolution must be done with only the functions
already imported.
There are multiple ways to complete this function. One possible solution would be to use 'tensordot'.
If you would like to index a tensor, you can do it as such:
tensor[y:y+height, x:x+width]
This returns a subtensor who's first element is tensor[y,x] and has height 'height, and width 'width'
"""
input_tensor_dimensions = input.shape
weight_dimensions = weight.shape
Output_Tensor = tensor(())
"*** YOUR CODE HERE ***"
input_height = input_tensor_dimensions[0]
input_width = input_tensor_dimensions[1]
weight_height = weight_dimensions[0]
weight_width = weight_dimensions[1]
output_height = input_height - weight_height + 1
output_width = input_width - weight_width + 1
output_rows = []
for y in range(output_height):
output_cols = []
for x in range(output_width):
input_subtensor = input[y:y + weight_height, x:x + weight_width]
output_value = (input_subtensor * weight).sum()
output_cols.append(output_value)
output_rows.append(torch.stack(output_cols))
Output_Tensor = torch.stack(output_rows)
"*** End Code ***"
return Output_Tensor
class DigitConvolutionalModel(Module):
"""
A model for handwritten digit classification using the MNIST dataset.
This class is a convolutational model which has already been trained on MNIST.
if Convolve() has been correctly implemented, this model should be able to achieve a high accuracy
on the mnist dataset given the pretrained weights.
Note that this class looks different from a standard pytorch model since we don't need to train it
as it will be run on preset weights.
"""
def __init__(self):
# Initialize your model parameters here
super().__init__()
output_size = 10
self.convolution_weights = Parameter(ones((3, 3)))
""" YOUR CODE HERE """
self.layer1 = Linear(676, 128)
self.layer2 = Linear(128, 64)
self.output_layer = Linear(64, output_size)
def run(self, x):
return self(x)
def forward(self, x):
"""
The convolutional layer is already applied, and the output is flattened for you. You should treat x as
a regular 1-dimentional datapoint now, similar to the previous questions.
"""
x = x.reshape(len(x), 28, 28)
x = stack(list(map(lambda sample: Convolve(sample, self.convolution_weights), x)))
x = x.flatten(start_dim=1)
""" YOUR CODE HERE """
x = relu(self.layer1(x))
x = relu(self.layer2(x))
x = self.output_layer(x)
return x
def get_loss(self, x, y):
"""
Computes the loss for a batch of examples.
The correct labels `y` are represented as a tensor with shape
(batch_size x 10). Each row is a one-hot vector encoding the correct
digit class (0-9).
Inputs:
x: a node with shape (batch_size x 784)
y: a node with shape (batch_size x 10)
Returns: a loss tensor
"""
""" YOUR CODE HERE """
scores = self.run(x)
loss = cross_entropy(scores, y)
return loss
def train(self, dataset):
"""
Trains the model.
"""
""" YOUR CODE HERE """
dataloader = DataLoader(dataset, batch_size = 64, shuffle = True)
optimizer = optim.Adam(self.parameters(), lr = 0.001)
max_epochs = 10
for epoch in range(max_epochs):
for batch in dataloader:
x = batch['x']
y = batch['label']
optimizer.zero_grad()
loss = self.get_loss(x, y)
loss.backward()
optimizer.step()
if hasattr(dataset, "get_validation_accuracy"):
validation_accuracy = dataset.get_validation_accuracy()
if validation_accuracy >= 0.85:
breakQ6.Attention
在这个问题中我们补充了一个Attention层的前向计算,跨度有点大难度有点高简单说一下:
首先关注三个变量K, Q, V:
Q = Query,我想找什么
K = Key,我有什么特征可以被别人找到
V = Value,我真正携带的信息Attention所做的事情就是用Q和K算匹配程度,匹配程度越高,就越关注对应的V
Causal Mask的实现在段落中已经给出,这是为了防止模型偷看未来用到的数据,不再做解释
片段解释
解释下面代码段
M = torch.matmul(K, Q_transpose) / (self.layer_size ** 0.5)假设序列长度为3: c a t , 那么Attention就想要得到一个3×3的表,其中每个?表示当前位置应该关注另一个位置多少
看 c 看 a 看 t
处理 c ? ? ?
处理 a ? ? ?
处理 t ? ? ?代码段的前半段得到的就是这个相关程度表
M = torch.matmul(K, Q_transpose)如果输入的shape为:
input.shape = (B, T, C)
"""
B = 32 个样本
T = 8 个字符
C = 128 维特征
"""那么就是:
K.shape = (B, T, C)
Q.shape = (B, T, C)
Q_transpose.shape = (B, C, T)
(K @ Q_transpose).shape = (B, T, T)实现代码
class Attention(Module):
def __init__(self, layer_size, block_size):
super().__init__()
"""
All the layers you should use are defined here.
In order to pass the autograder, make sure each linear layer matches up with their corresponding matrix,
ie: use self.k_layer to generate the K matrix.
"""
self.k_layer = Linear(layer_size, layer_size)
self.q_layer = Linear(layer_size, layer_size)
self.v_layer = Linear(layer_size,layer_size)
#Masking part of attention layer
self.register_buffer("mask", torch.tril(torch.ones(block_size, block_size))
.view(1, 1, block_size, block_size))
self.layer_size = layer_size
def forward(self, input):
"""
Applies the attention mechanism to input. All necessary layers have
been defined in __init__()
In order to apply the causal mask to a given matrix M, you should update
it as such:
M = M.masked_fill(self.mask[:,:,:T,:T] == 0, float('-inf'))[0]
For the softmax activation, it should be applied to the last dimension of the input,
Take a look at the "dim" argument of torch.nn.functional.softmax to figure out how to do this.
"""
B, T, C = input.size()
"""YOUR CODE HERE"""
K = self.k_layer(input)
Q = self.q_layer(input)
V = self.v_layer(input)
Q_transpose = torch.movedim(Q, 1, 2)
M = torch.matmul(K, Q_transpose) / (self.layer_size ** 0.5)
M = M.masked_fill(self.mask[:, :, :T, :T] == 0, float('-inf'))[0]
attention_weights = torch.nn.functional.softmax(M, dim = -1)
output = torch.matmul(attention_weights, V)
return output