Hidden Markov Models
我们在之前学习到了马尔可夫模型,并且着重点放在了状态随时间怎么变化。但是现实情况是,有很多真实状态我们观测不到。所以说我们正式引入HMM( Hidden Markov Models ).
状态依然按照
Markov chain演化,但每个时刻都会产生一个可以观测的evidence variable,相当于每走一步观测一次
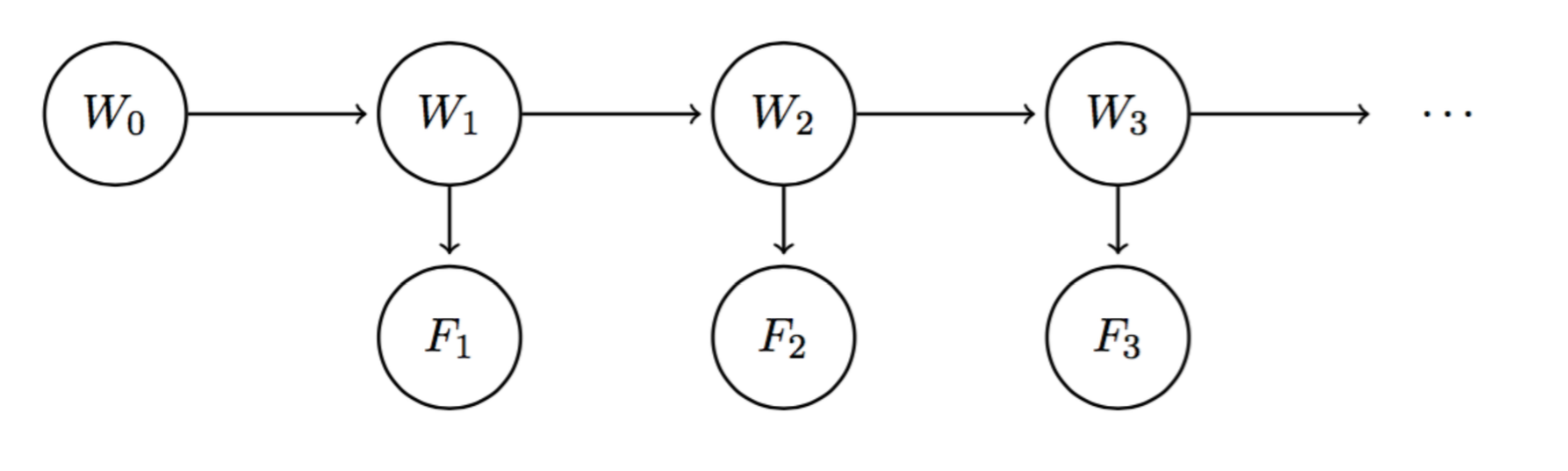 需要提及的是在原Note中给出的一些独立性变量,我们可以回顾一下Note13的内容,图中展示的内容全部为
需要提及的是在原Note中给出的一些独立性变量,我们可以回顾一下Note13的内容,图中展示的内容全部为因果链( Causal Chain ),有一个变量被观测,则被观测节点的+n节点和-n节点都是相互独立的
- 我们在这里依旧定义转移函数为,
- 定义
sensor model为, - 定义
belief distribution即为已知到当前为止的所有观测,系统现在处于各个隐藏状态的概率是多少, - 类似的,我们定义在i状态下,还没有在此刻采取观测的
belief为
HMM两个关键独立性假设
状态转移仍然满足马尔可夫性
在Note7,我们提及到了马尔可夫性,即可以简单理解为给定当前状态s ( 以及当前动作a ) 后未来的下一步action概率分布不受过去的任何行为影响 → 只需要当前状态即可预测未来行为
当前观测只依赖当前状态
Forward Algorithm
该算法是HMM版本的递推更新办法,用来不断更新belief distribution
第一步:Time elapse update
这一步先不看新观测,只根据转移模型来把旧的belief往前推一格:
第二步:Observation update
再把新的观测融合进来:
这里的∝表示“成比例”,因为乘完之后总和不一定是 1, 所以最后要把所有项除以总和,变回真正的概率分布。
整体公式
Forward Algorithm实例
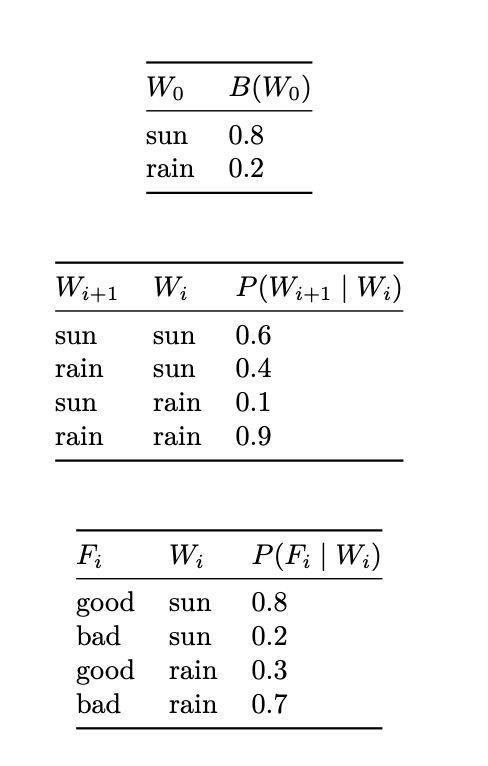
 这里需要解释一下,我怀疑过一个问题: 即我已经观测到了”good forecast”,为什么我用的是,难道F不是被观测了吗?
这里需要解释一下,我怀疑过一个问题: 即我已经观测到了”good forecast”,为什么我用的是,难道F不是被观测了吗?
我们需要理解的是是在衡量这个观测有多合理。
Observation update不是在算“观测的概率”,而是在用观测去给不同状态打分
Viterbi Algorithm
我们在Forward algorithm中已经讨论到了当前在哪个状态的概率最大,我们现在提及到的算法Viterbi Algorithm求的是在所有可能的隐藏序列中,哪一条路径整体概率最大
Viterbi Algorithm想要求的是
因为证据已经固定住了,所以说等价于求
从到的边权重可以写成
其中
- 第一项表示转移有多自然
- 第二项表示当前观测和这个状态有多匹配
整条路径概率,就是这些边权重连乘,再乘上初始项
这是非常典型的
Dynamic Programming,因为如果我们想知道“到达时刻 t的某个状态的最佳路径”,只需要知道上一时刻每个状态的最佳路径概率,再选一个最优前驱接过来即可
为什么不能每一步都贪心选最大状态
很多人容易误以为:
- 第 1 时刻选概率最大的状态
- 第 2 时刻再选概率最大的状态
- … 这样拼起来就是最优路径。 但这通常不对,因为“某一时刻最可能的单个状态”拼起来,不一定构成“全局概率最大的完整路径”。 Viterbi 的关键就在于:
它优化的是整条 path 的联合概率,而不是每个时刻单独最优。
State Trellis
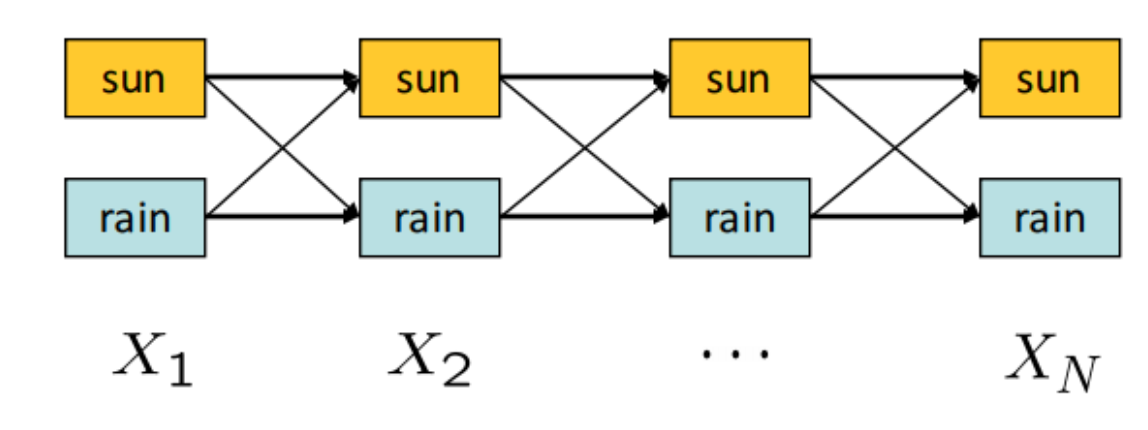 我们可以通过该图来理解Viterbi
我们可以通过该图来理解Viterbi
- 横轴是时间 1,2,…,N
- 每一列是这个时刻可能的 hidden states
- 相邻两列之间用边连接,表示可能的状态转移 这样,一条从左到右的路径就表示一个完整的 hidden-state sequence
Viterbi algorithm 用 dynamic programming 在 state trellis 上寻找给定观测序列下概率最高的 hidden-state sequence,本质是把 Forward 里的求和换成取最大,并通过 backpointers 恢复整条路径