共享Open file description
首先我们先来回顾一下之前提及过的File descriptor和Open file description的区别,在Note5我们提过。进程内部有一个File descriptor table,其中一个位置指向了内核中的内核结构体Open file description。
Fork
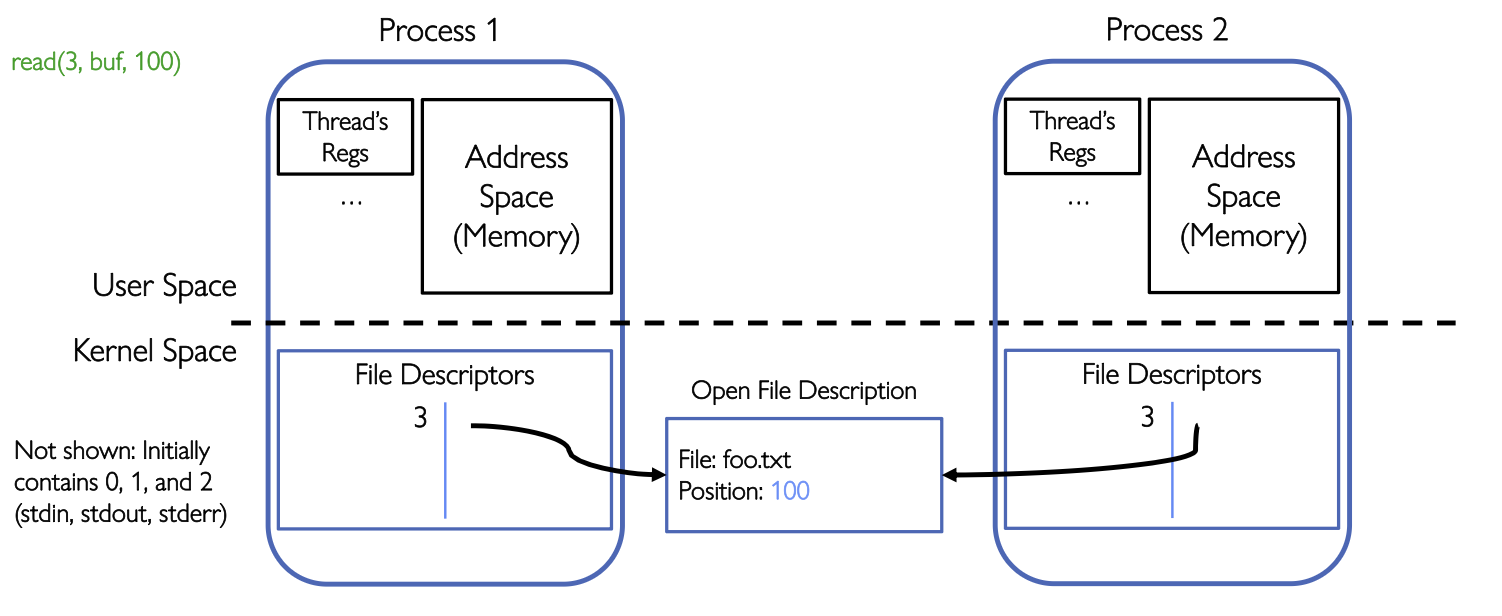 当我们
当我们fork()一个进程的时候:
- 子进程得到父进程
file descriptor table的副本 - 但这些fd指向同一个
open file description这样导致的结果就是,当父进程子进程任意一个行为导致对Open file descriptor的修改都会让双方的Open file descriptor都发生改变,因为本质上是同一个。 比如说read(3, buf, 100)操作,意思是在buf中读取100个字节。如果成功读取了100个字节,那么Open file description里的position会从0变100,文件偏移量不是简单存在用户程序变量里,而是在内核的Open file description中维护。 如果父进程先执行read(3, buf, 100)文件的offset从100变成了200,然后子进程再执行read(3, buf, 100)它就会从offset 200开始读。
Close
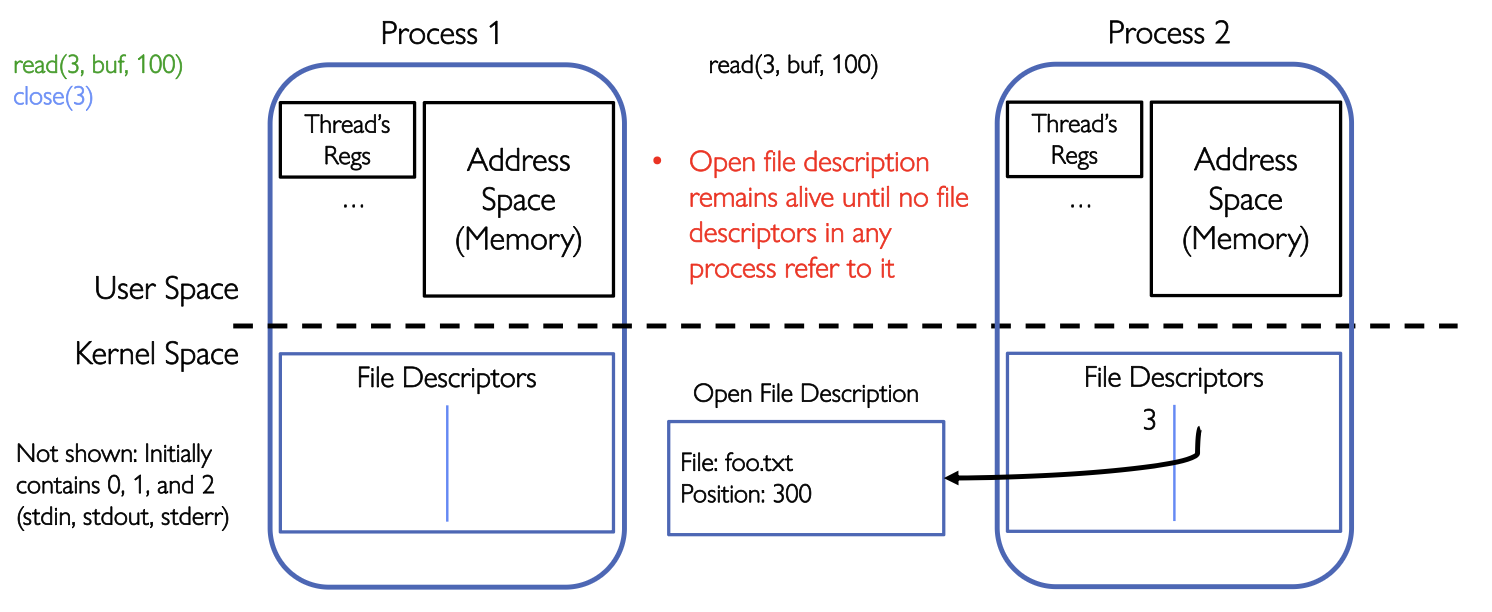
如果父进程执行close(3)的话,只是父进程关闭自己的fd 3,如果子进程还有fd 3指向了同一个Open file description的话,那么该Open file description不会被销毁。
没有任何进程的
File descriptor指向Open file description的时候,内核才会释放Open file description
Advantage
这样做的优点很明显,它允许进程之间共享资源
Example of its advantage
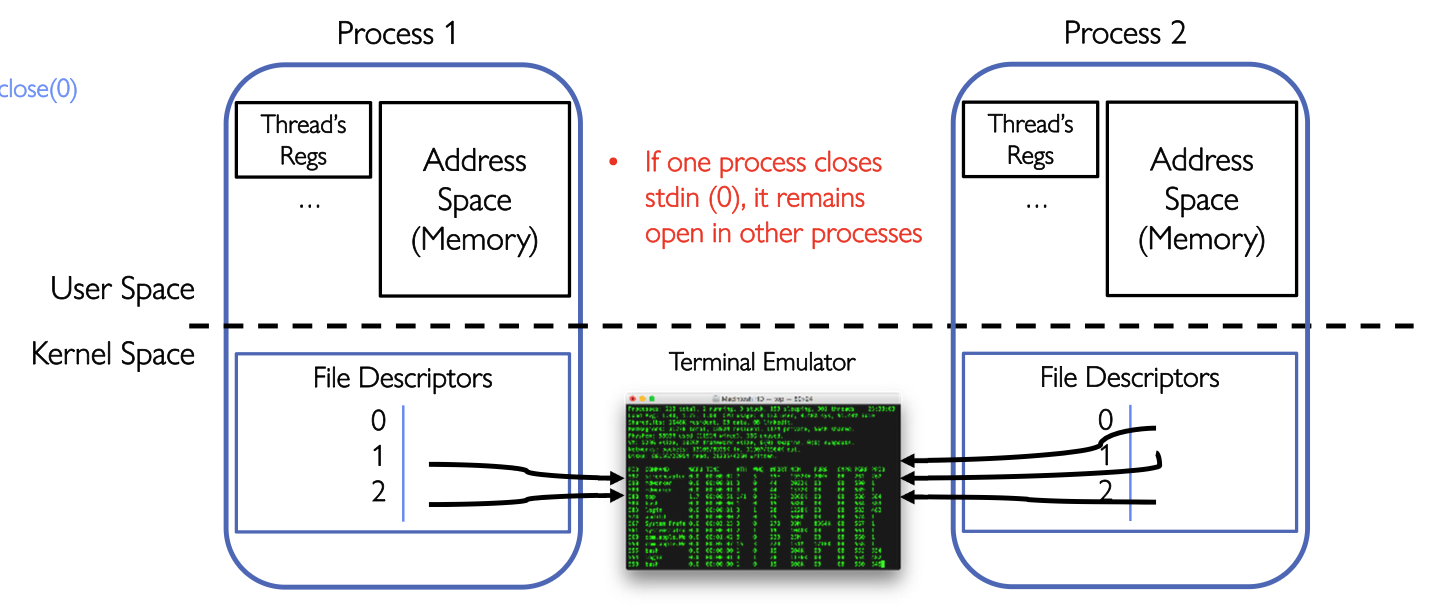
我们给一个有关Shared Terminal Emulator的例子来理解这个Advantage:
父子进程是共享一个终端的,假设都有stdout指向了同一个terminal,所以fork()了之后进行printf(...)父子进程都可以输出到同一个终端。
但是如果某个进程关闭了自己的stdin,不会导致其它进程的stdin也被关闭
Pipe
我们在Note5中提及到了一种IPC的方法Socket,我们在这里阐明第二种方法Pipe
单进程Pipe
下面代码所阐释的内容是单进程pipe,自己写pipe再自己读pipe
#include <unistd.h>
int main(int argc, char *argv[])
{
char *msg = "Message in a pipe.\n";
char buf[BUFSIZE];
int pipe_fd[2];
if (pipe(pipe_fd) == -1) {
fprintf (stderr, "Pipe failed.\n"); return EXIT_FAILURE;
}
ssize_t writelen = write(pipe_fd[1], msg, strlen(msg)+1);
printf("Sent: %s [%ld, %ld]\n", msg, strlen(msg)+1, writelen);
ssize_t readlen = read(pipe_fd[0], buf, BUFSIZE);
printf("Rcvd: %s [%ld]\n", msg, readlen);
close(pipe_fd[0]);
close(pipe_fd[1]);
}pipe()创建了一个单向通道:
int pipe_fd[2];
pipe(pipe_fd)通常来说是:
fd 0 = stdin
fd 1 = stdout
fd 2 = stderr
pipe_fd[0]用来读,就是fd 3
pipe_fd[1]用来写,就是fd 4多进程Pipe
多进程Pipe多发生在父子进程之间
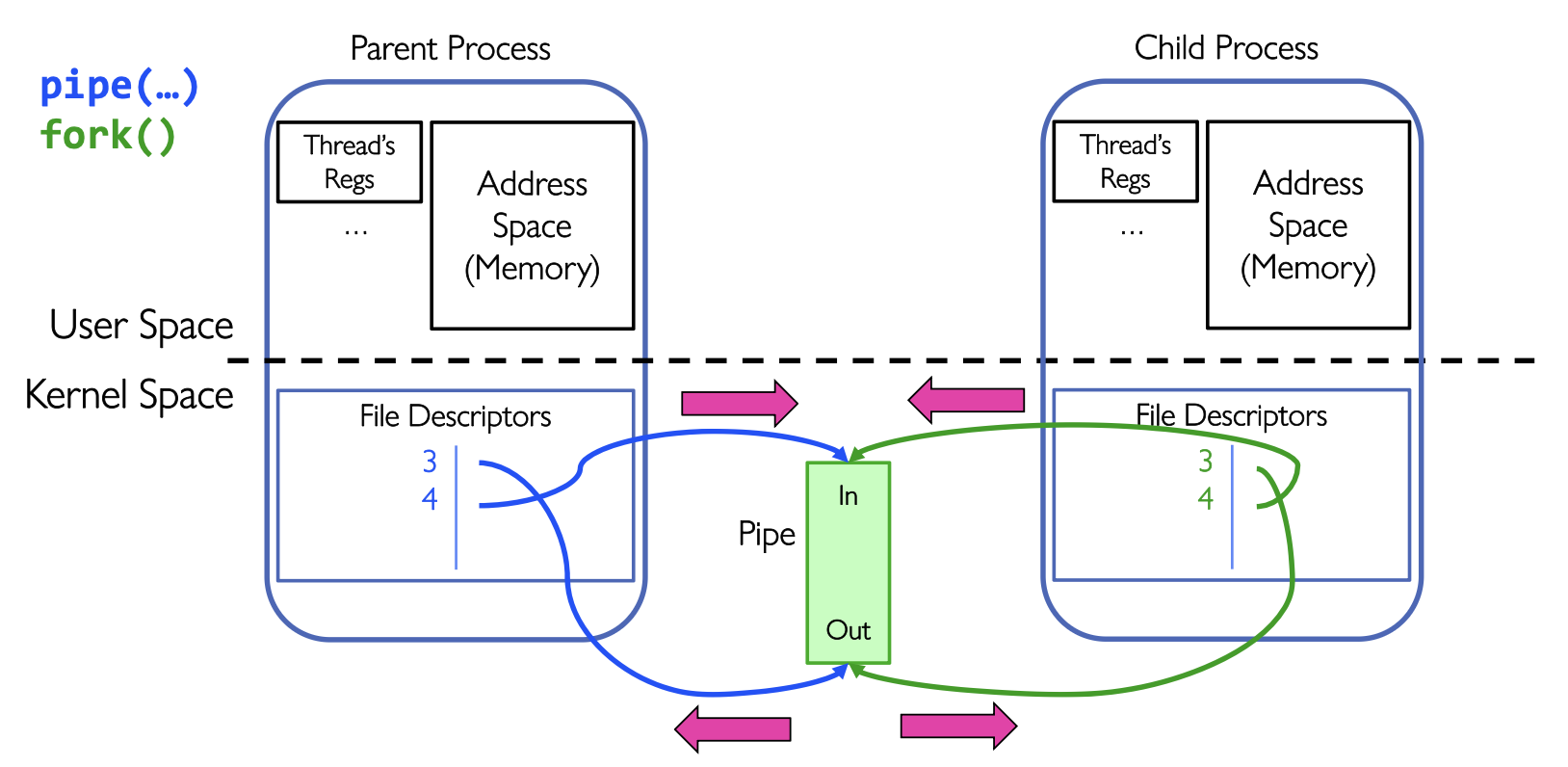 进行了
进行了fork()之后父子进程都有了pipe的读端和写端
如果想要建立父进程到子进程的单向通道,父进程只写子进程只读:
父进程关闭读端:
close(pipe_fd[0]);
write(pipe_fd[1], msg, msglen);子进程关闭写端:
close(pipe_fd[1]);
read(pipe_fd[0], buf, BUFSIZE);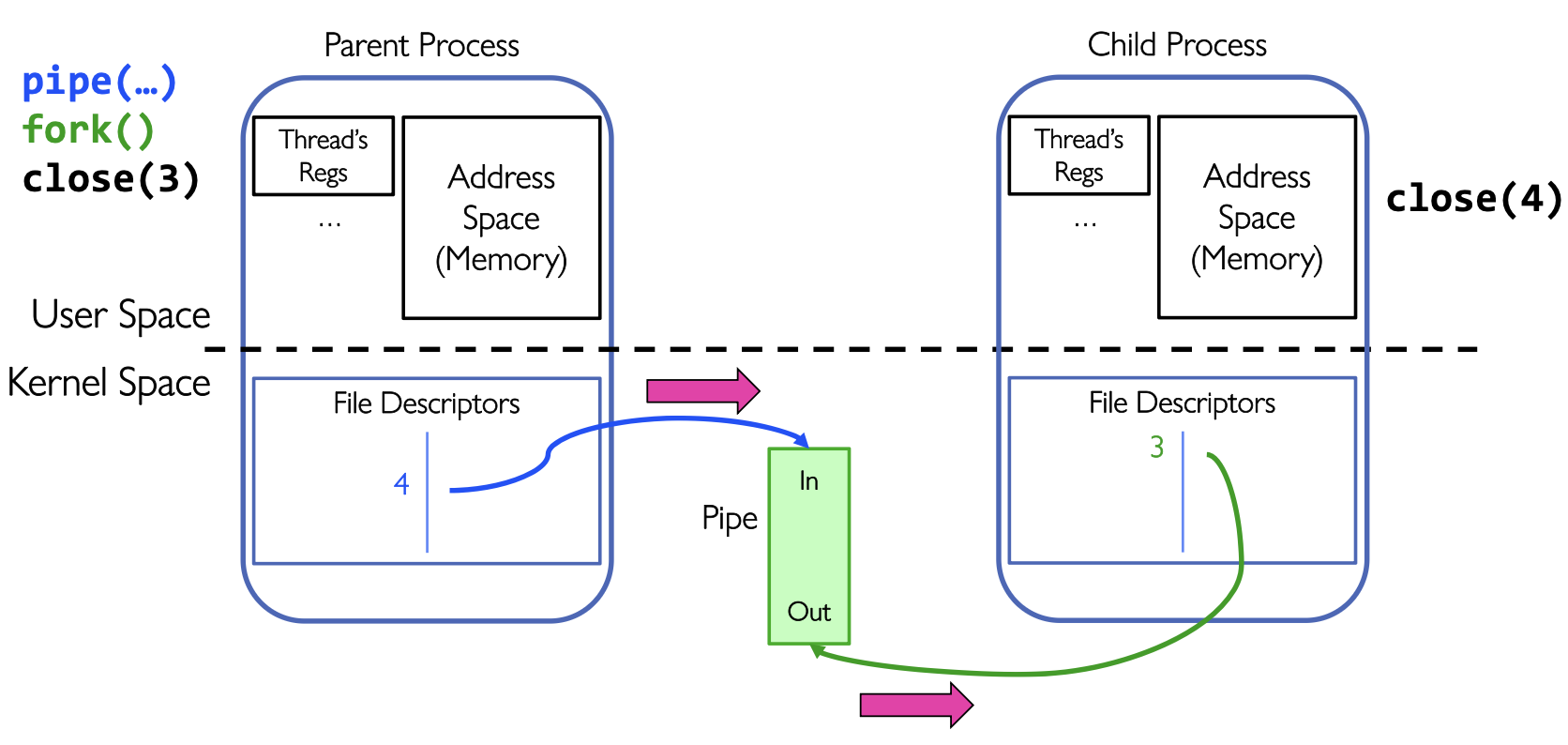
Dispatch Loop
OS的调度循环可以抽象成为:
Loop {
RunThread();
ChooseNextThread();
SaveStateOfCPU(curTCB);
LoadStateOfCPU(newTCB);
}这体现了操作系统调度的基本工作:
- 运行当前线程;
- 当前线程由于某种原因停止运行;
- 选择下一个线程;
- 保存当前线程状态;
- 恢复下一个线程状态;
- 让下一个线程继续执行。
这里引出我们的核心问题:即当我们进行了
RunThead()之后,操作系统该怎么样才能重新拿回CPU的控制权?因为当用户线程运行的时候,CPU正在执行的是用户代码而不是操作系统的代码。
OS拿回控制权
OS拿回控制权的方法通常分为两类:
Internal Events
这是内部事件,线程会主动或间接让出CPU
Blocking I/O
例如线程执行下面的代码
read(fd, buf, size);如果数据还没有准备好,那么线程就会阻塞。阻塞的时候,OS可以切换到其它的进程
Waiting on join
例如一个线程等待另一个线程完成
join(...)等待期间当前的线程不需要继续占用CPU
yield
当线程主动调用yield()的时候,意思就是当前线程主动放弃了CPU的使用权
External Events
这是外部事件,OS的外部机制来强行打断它,就是我们之前提及到的Interrupt
Context Switch
Context Switch指的是:
保存当前线程的CPU状态,并恢复另一个线程的CPU状态
需要保存和恢复的内容包括了:
- general-purpose registers;
- stack pointer;
- program counter / return PC;
- 其他架构相关状态 其中的伪代码类似于:
Switch(tCur, tNew) {
TCB[tCur].regs.r7 = CPU.r7;
...
TCB[tCur].regs.sp = CPU.sp;
TCB[tCur].regs.retpc = CPU.retpc;
CPU.r7 = TCB[tNew].regs.r7;
...
CPU.sp = TCB[tNew].regs.sp;
CPU.retpc = TCB[tNew].regs.retpc;
return;
}每个线程都有自己的栈
我们再次强调一下,每个线程都有自己的栈,这个思想在我们第一次讲到Note2中的Single and Multithreaded Processes就提及到过,那张图表示的很清楚
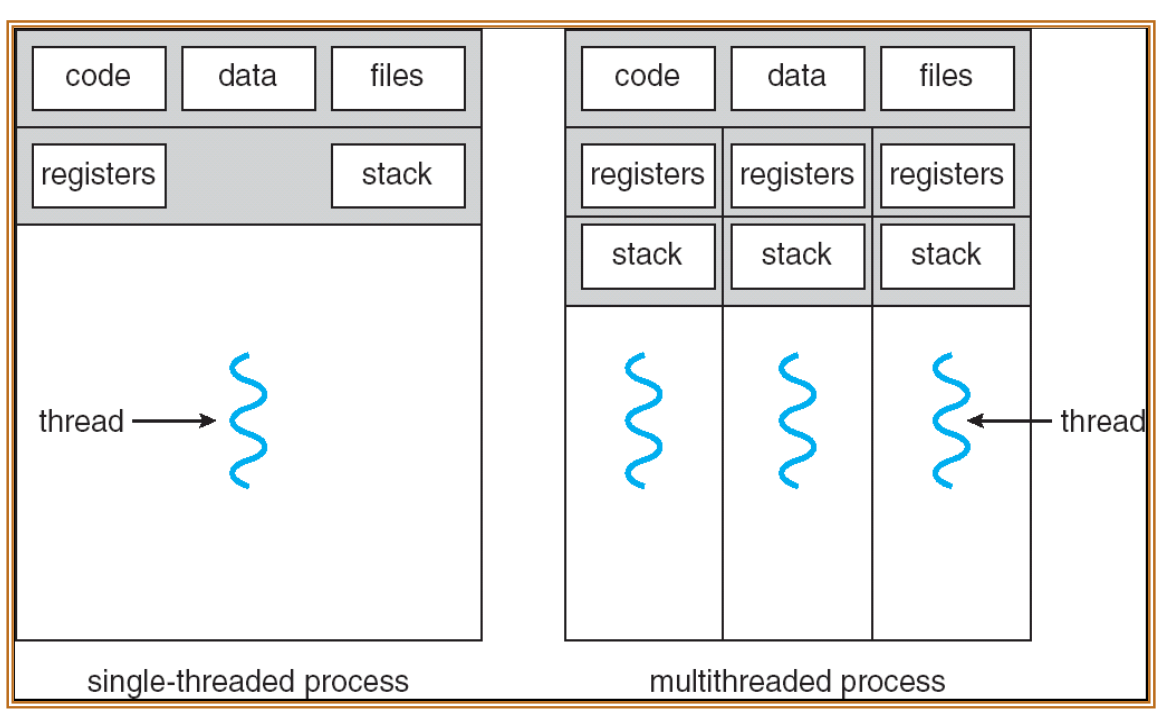 并且我们在Note3提及到过,每个线程还有
并且我们在Note3提及到过,每个线程还有Kernel Stack,用户态的栈和内核态的栈是分开的
Switch Details
别的不多说,这一部分就只是告诉我们一件事:
操作系统底层代码,尤其是 context switch 这种核心代码,不要为了省一点点性能而搞复杂技巧。
一旦出现错误,整个系统都会不可靠;这种错误非常隐蔽,测试很难完全覆盖,未来维护者可能忘记原来的特殊前提。
Context Switch的代价
Linux参考数据:
- context switch 频率大概是 10–100ms;
- process switch 大概 3–4 μs;
- thread switch 大概 100ns;
- 同一进程内线程切换更便宜,因为不需要切换地址空间。
Interrupts
我们又回到了刚才的问题,如果线程不主动交出CPU,OS仍然需要调度。
我们先回顾一下Interrupt Controller的作用,在Note3我们第一次涉及。其核心概念就是
Device raises interrupt
↓
Interrupt controller selects interrupt
↓
CPU jumps to interrupt handlerNetwork Interrupt
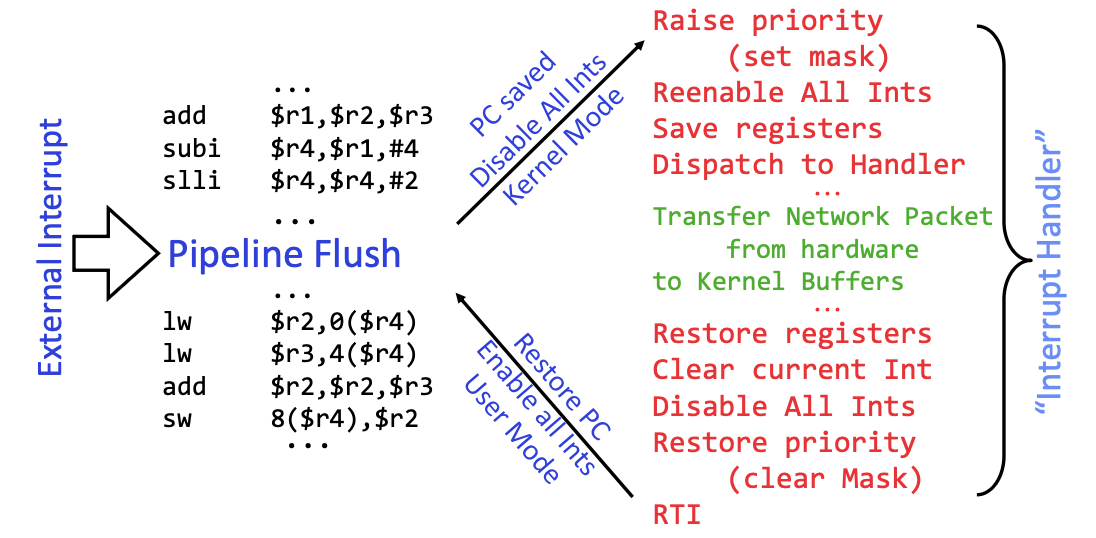 和普通线程切换不同的是,中断发生的时候,CPU 立即转去执行 interrupt handler;普通调度需要选择下一个线程
和普通线程切换不同的是,中断发生的时候,CPU 立即转去执行 interrupt handler;普通调度需要选择下一个线程
Timer Interrupt
Timer Interrupt可以用来抢占线程
TimerInterrupt() {
DoPeriodicHouseKeeping();
run_new_thread();
}它可以做周期性维护,调用调度器,切换另一个线程等等。
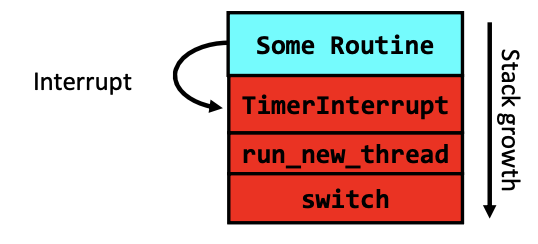
ThreadFork
ThreadFork()是一个用户级别的过程,它创建一个新的线程并把它放在已经准备好的队列里。
它通常需要三个参数:
- 函数指针
fcnPtr - 参数指针
fcnArgPrt - 新线程栈大小
新线程是怎么被启动的
新线程创建之后,并不是马上运行的。而是被放到一个ready queue等到调度器 run_new_thread()选中它的时候,它才开始执行,如下图所示:switch()恢复新线程的状态的时候,就会跳到ThreadRoot()的开头
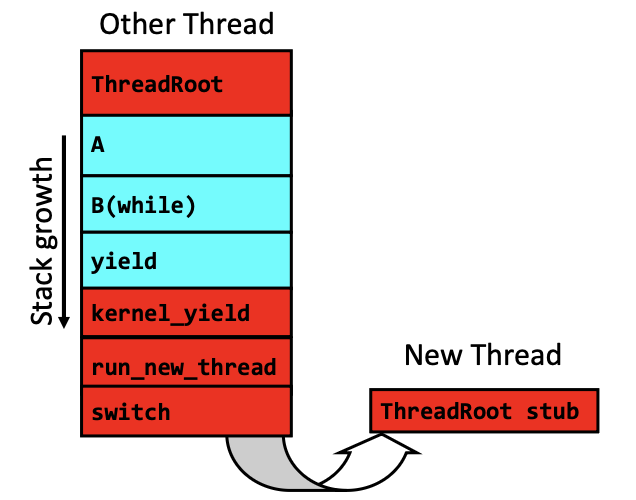 我们思考一个问题,
我们思考一个问题,ThreadFork()是创建一个新的线程。普通线程切换的时候,OS做的事情是保存当前线程现场,然后恢复另一个线程的现场。但是新线程之前从来没有运行过,哪里来的现场?所以OS就人为构造一个初始现场:
SP 指向新栈
PC 指向 ThreadRoot
参数寄存器里放 fcnPtr 和 fcnArgPtr伪代码是
SetupNewThread(tNew) {
...
TCB[tNew].regs.sp = newStackPtr;
TCB[tNew].regs.retpc = &ThreadRoot;
TCB[tNew].regs.r0 = fcnPtr;
TCB[tNew].regs.r1 = fcnArgPtr;
}ThreadRoot
ThreadRoot()具体结构如下:
ThreadRoot(fcnPtr, fcnArgPtr) {
DoStartupHousekeeping(); /* 做线程启动前的记录和初始化 */
UserModeSwitch(); /* enter user mode */
Call fcnPtr(fcnArgPtr);/* 调用用户真正想运行的线程函数 */
ThreadFinish();
}总流程
用户调用 ThreadFork(fcnPtr, fcnArgPtr)
↓
OS 分配新的 TCB
↓
OS 分配新的 Stack
↓
初始化 TCB:
sp = 新栈地址
retpc = ThreadRoot
参数寄存器 = fcnPtr 和 fcnArgPtr
↓
把新线程放入 ready queue
↓
某次调度时 run_new_thread() 选中新线程
↓
switch() 恢复新线程的寄存器状态
↓
CPU 从 ThreadRoot() 开始执行
↓
ThreadRoot() 调用 fcnPtr(fcnArgPtr)
↓
线程函数运行
↓
线程函数返回
↓
ThreadRoot() 调用 ThreadFinish()
↓
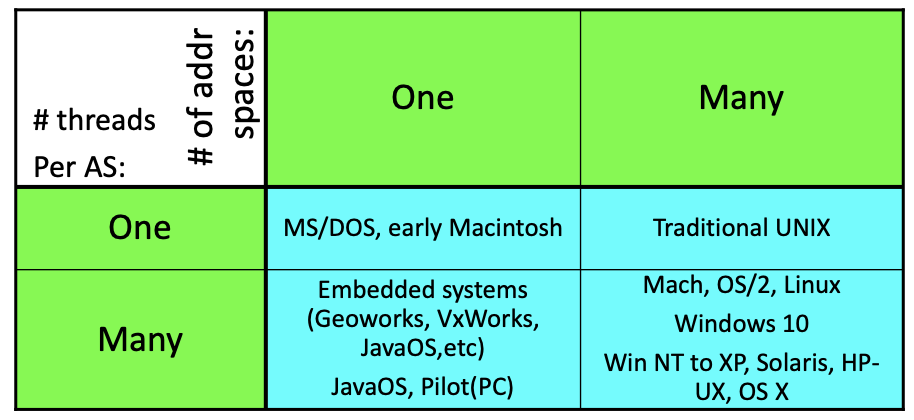
线程结束Threads vs Address Space
Concurrency vs Parallelism
并发和并行的区别很简单:
- 并发指的是多个线程在执行时间上可以交错,只有一个CPU也可以并发。调度器可以用任意顺序执行线程
- 并行指的是多个线程真的在同一时刻运行,这就需要多个CPU core了
ATM Server
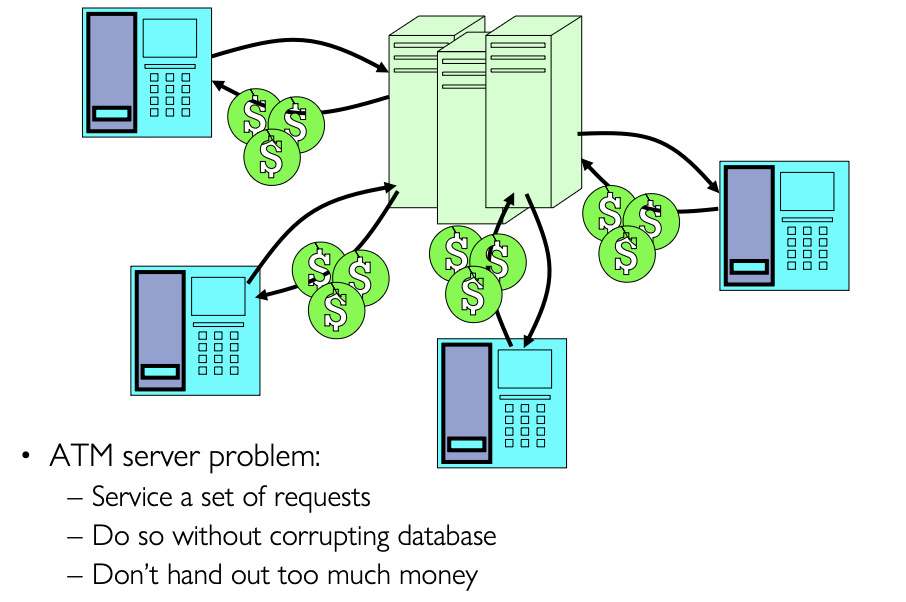 服务器要处理多个ATM请求:
服务器要处理多个ATM请求:
BankServer() {
while (TRUE) {
ReceiveRequest(&op, &acctId, &amount);
ProcessRequest(op, acctId, amount);
}
}存款操作是:
Deposit(acctId, amount) {
acct = GetAccount(acctId); // may use disk I/O
acct->balance += amount;
StoreAccount(acct); // involves disk I/O
}想要让ATM Server加速,我们有三种方法:
- 多个请求同时处理
- Event-driven,通过事件驱动重写程序,重叠I/O和计算
- Multi-threaded,一个请求一个线程,线程可以阻塞,不影响其它线程继续执行
Event-driven Server
BankServer() {
while(TRUE) {
event = WaitForNextEvent();
if (event == ATMRequest)
StartOnRequest();
else if (event == AcctAvail)
ContinueRequest();
else if (event == AcctStored)
FinishRequest();
}
}这个方法优点很显然,单线程也可以处理多个I/O。但是PDF里面提出了一个问题:
What if we have to split code into hundreds of pieces which could be blocking?
这是event-driven编程的一个大痛点
Multi-threaded
Deposit(acctId, amount) {
acct = GetAccount(acctId);
acct->balance += amount;
StoreAccount(acct);
}每个请求一个线程,线程自己阻塞等待I/O。代码很容易理解,但是如果两个线程同时给一个账户存钱呢?这就引出了一个很大的问题----Race Condition
Race Condition
假设两个线程同时给一个账户存钱,里面原来有100,线程1存了10:
acct->balance += 10;线程2存了20:
acct->balance += 20;按理来说是有130,但是+=不是一条不可分割操作,它可能被拆成了
load balance
add amount
store balance可能会出现下面的interleaving:
Thread 1: load balance = 100
Thread 2: load balance = 100
Thread 2: add 20 => 120
Thread 2: store 120
Thread 1: add 10 => 110
Thread 1: store 110线程2的更新丢失了,这就是典型的Race Condition
这种现象的本质就是:
程序结果依赖多个线程的执行程序
Data Race And Critical Section
Data Race
当多个线程满足以下条件时,就可能发生 data race:
- 访问同一份共享数据;
- 至少一个线程在写;
- 没有使用同步机制。 例如:
balance = balance + amount;如果多个线程同时执行,就可能 data race
Critical Section
Critical Section指的是访问共享资源,必须保证互斥执行的代码区域
acct = GetAccount(acctId);
acct->balance += amount;
StoreAccount(acct);如果多个线程可能操作同一个账户,那么这段代码就是Critical Section
Mutual Exclusion
Mutual Exclusion的意思是同一时刻最多只能有一个线程进入Critical Section,也就是互斥,常见的实现就是lock
lock.acquire();
acct = GetAccount(acctId);
acct->balance += amount;
StoreAccount(acct);
lock.release();这样保证一个线程修改账户的时候其它线程必须等待,这样就不会出现更新丢失了
Atomic Operation
Atomic Operation的中文名叫做原子操作,它的含义是原子操作要么完整执行玩,要么完全不执行,不会停留在中间。如果没有任何原子操作,线程之间就没有可靠的合作基础,因为任何同步机制最终都要建立在某种不可分割的底层操作上。
普通赋值不一定可以让线程完全安全,很多指令它并不是原子操作。锁、信号量、条件变量等高级同步工具,底层都需要依赖原子操作。