File Descriptor 和 Open File Description
我们在上一次Note4中第一次提及到了File Descriptor,但是我们并没有给出明确定义。这里我们正式给出我们的定义:
File Descriptor
file descriptor 是一个 int。它是进程视角看到的“句柄”, 课件强调它只是一个编号。注意注意只是一个int,没别的含义
int fd = open("a.txt", O_RDONLY); //这里的fd可能是3,4,5这种数字Open File Description
真正的文件状态在kernel内部,通常称作open file description。它是一个内核结构体,里面保存文件的各种信息。其中就至少包含了:
- 文件数据在哪里
- 当前偏移量
From Syscall To Driver
这里我们举了一个例子来了解内核真正发生了什么,我们用的是Linux内核里的vfs_read()代码来讲这一层,文件代码如下
先来理解函数的传入参数,其它理解注释在代码里面:
- 从
file读 - 最多读
count个字节 - 放到用户空间
buf - 从文件位置
pos开始 - 返回错误码或者成功读取的字节数
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
// 检查文件是否允许读,如果没有权限直接返回错误
if (!(file->f_mode & FMODE_READ)) return -EBADF;
// 检查文件/驱动是否支持read,并非所有的"文件对象"都一定支持read
// 这要看它有没有对应的操作函数
if (!file->f_op || (!file->f_op->read && !file->f_op->aio_read))
return -EINVAL;
// 检查用户缓冲区是否合法
// 为什么是VERIFY_WRITE? 因为内核要把数据写进用户buffer
// 如果buffer不是合法的用户空间地址,就不能写
// 这里的unlikely()是给分支预测的提示:这个错误通常不常发生
if (unlikely(!access_ok(VERIFY_WRITE, buf, count))) return -EFAULT;
// 检查读取范围是否合法,判断读取范围和偏移量是否有问题
ret = rw_verify_area(READ, file, pos, count);
if (ret >= 0) {
count = ret;
// 这里的第一个if-else判断是真正的read实现
// 意思是如果驱动/文件系统提供了专门的read方法,就去调用
// 否则走通用同步读逻辑do_sync_read()
if (file->f_op->read)
ret = file->f_op->read(file, buf, count, pos);
else
ret = do_sync_read(file, buf, count, pos);
if (ret > 0) {
fsnotify_access(file->f_path.dentry);
add_rchar(current, ret);
}
inc_syscr(current);
}
return ret;
}这里想要表达的真正含义,正是
A system call is not just “do the operation”; it is “validate, dispatch, account, then operate.”
Device Driver
课件里面给出的定义是:
Device driver is device-specific code in the kernel that interacts directly with the device hardware.
也就是它是内核中的一段代码,不仅直接和硬件交互也对上层提供标准接口。我们再来回顾一下下面这张图清晰一下它的位置
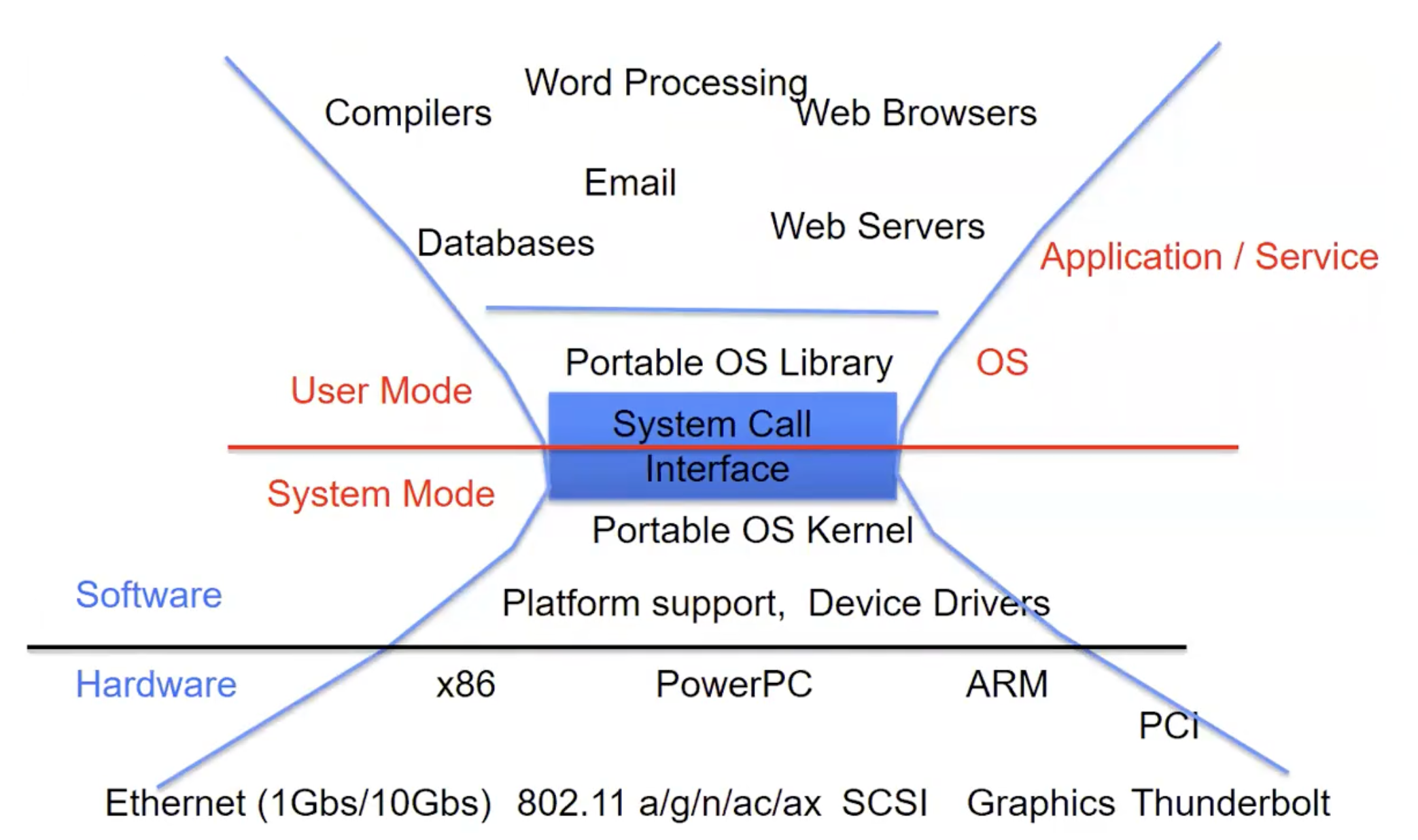
Device Driver的两个部分
Top Half
- 处于
Syscall的调用路径中 - 实现标准操作比如
open(),close(),read(),write,ioctl() - 可以启动
I/O - 可能会让线程睡眠等待完成
Bottom Half
- 通常由中断触发
- 在设备完成输入/输出的时候运行
- 处理下一批数据
Driver Dispatch Table
Device Driver中有一个dispatch table,里面存放各种file operation handler,这就是一种函数指针表的设计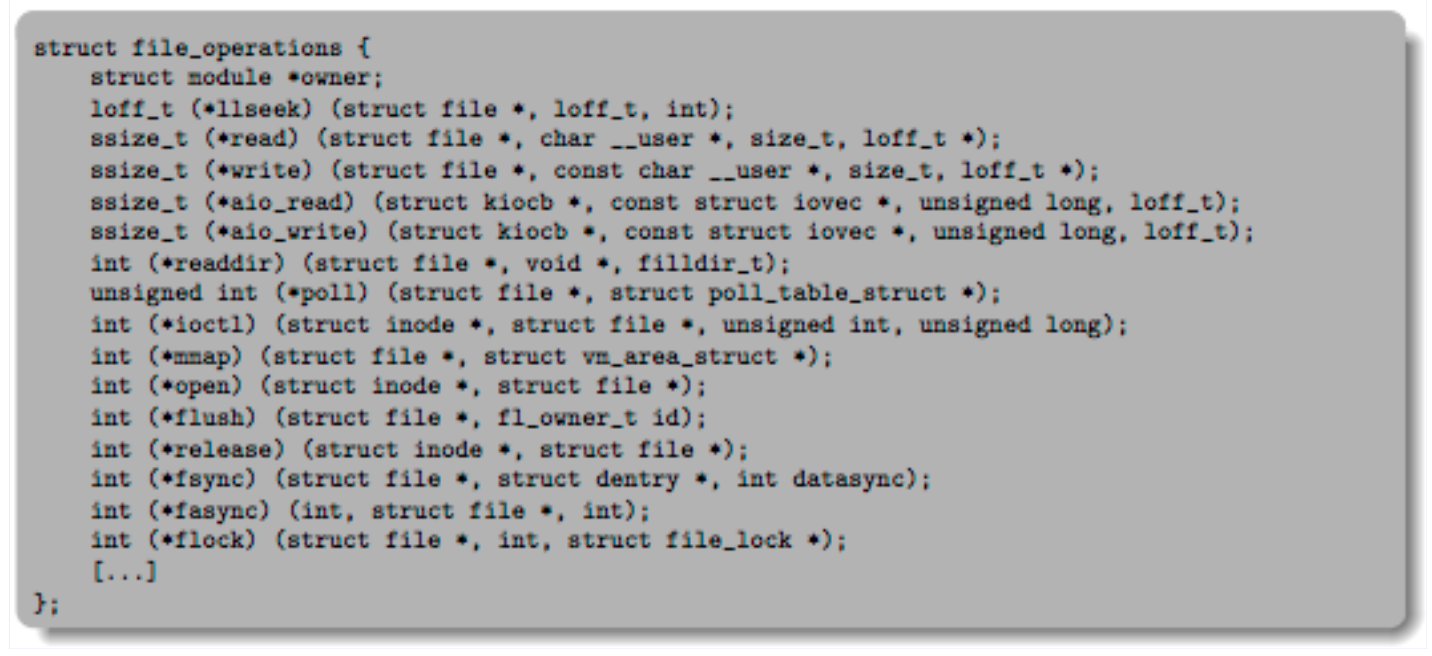 即使面对不同的设备,内核也能通过统一接口调用对应实现
即使面对不同的设备,内核也能通过统一接口调用对应实现
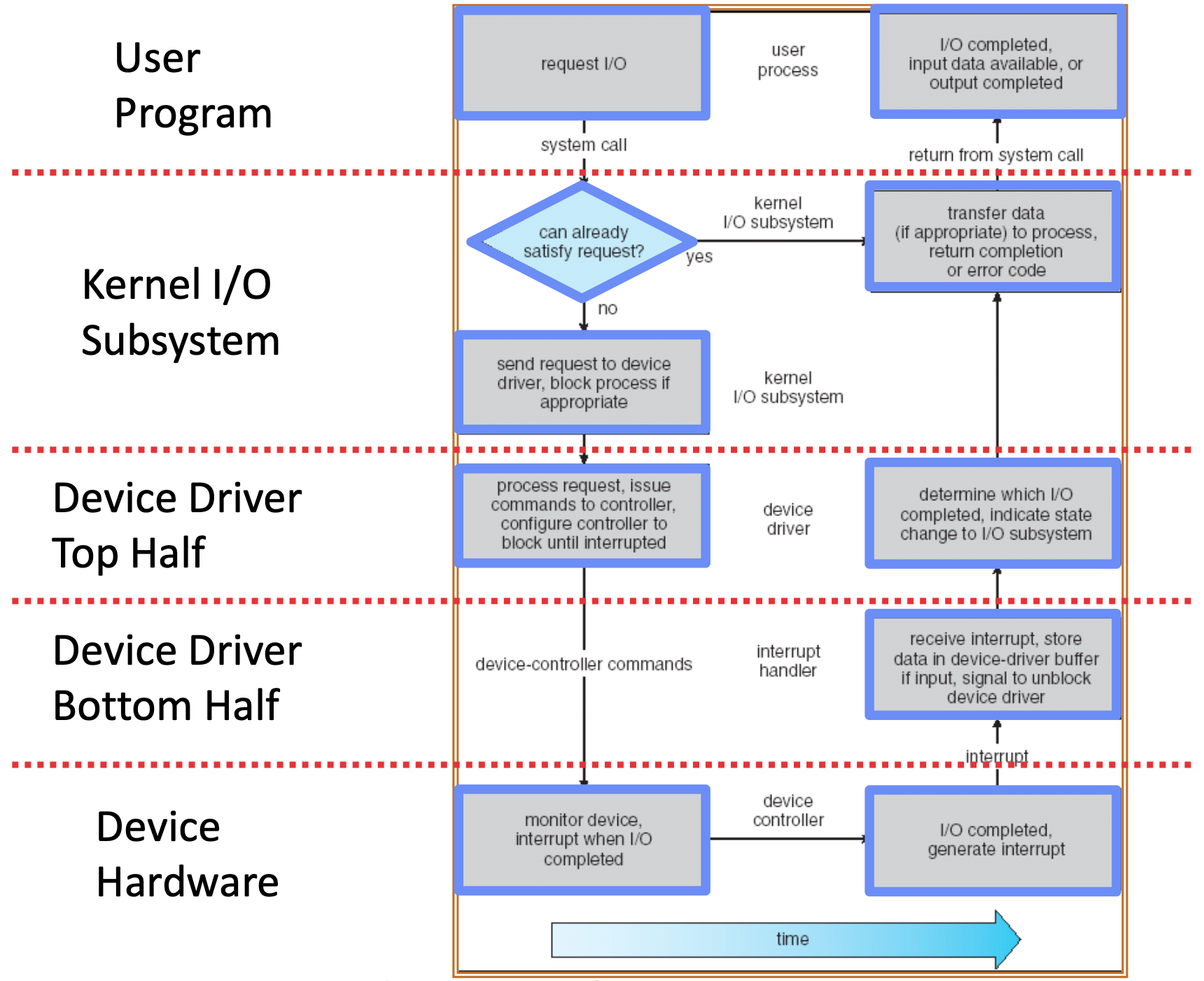
Life Cycle Of An I/O Request
IPC: Inter-Process Communication
我们首先回顾一下Process的概念, 默认情况下进程之间信息不会自动流入流出。要进行通信的话必须显式设置机制,这就是我们的IPC.这一讲列举了很多方式:
- file-like communication
- pipe
- socket
File As Communication Channels
首先我们思考一下,我们能不能创建一个文件当作它们之间的交流通道?也就是我们有一个进程写文件,另一个进程读文件,这实际上就实现了Communication。但是它并不完美:
因为如果数据是写一次再读一次,我们更希望它是一个queue,有着FIFO的特性,而不是一个持久的文件。所以文件适合作为一种持久化的数据交换,而不是临时通信。
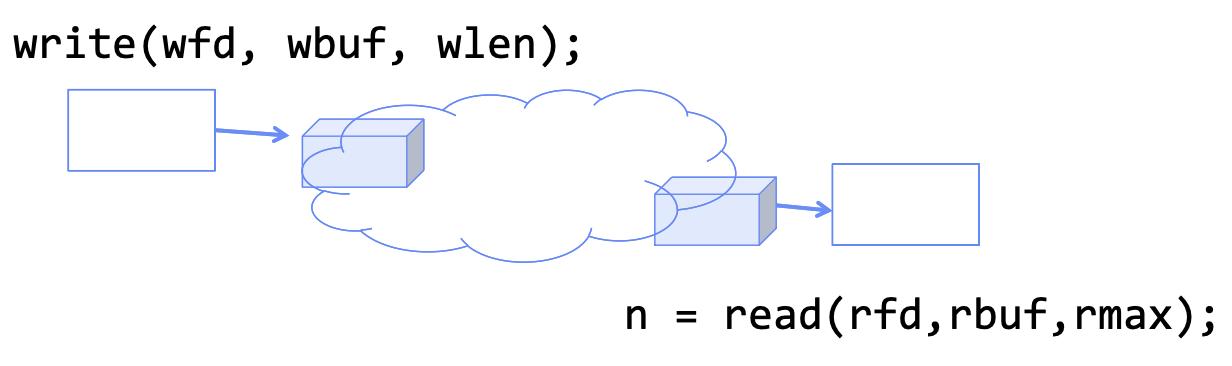
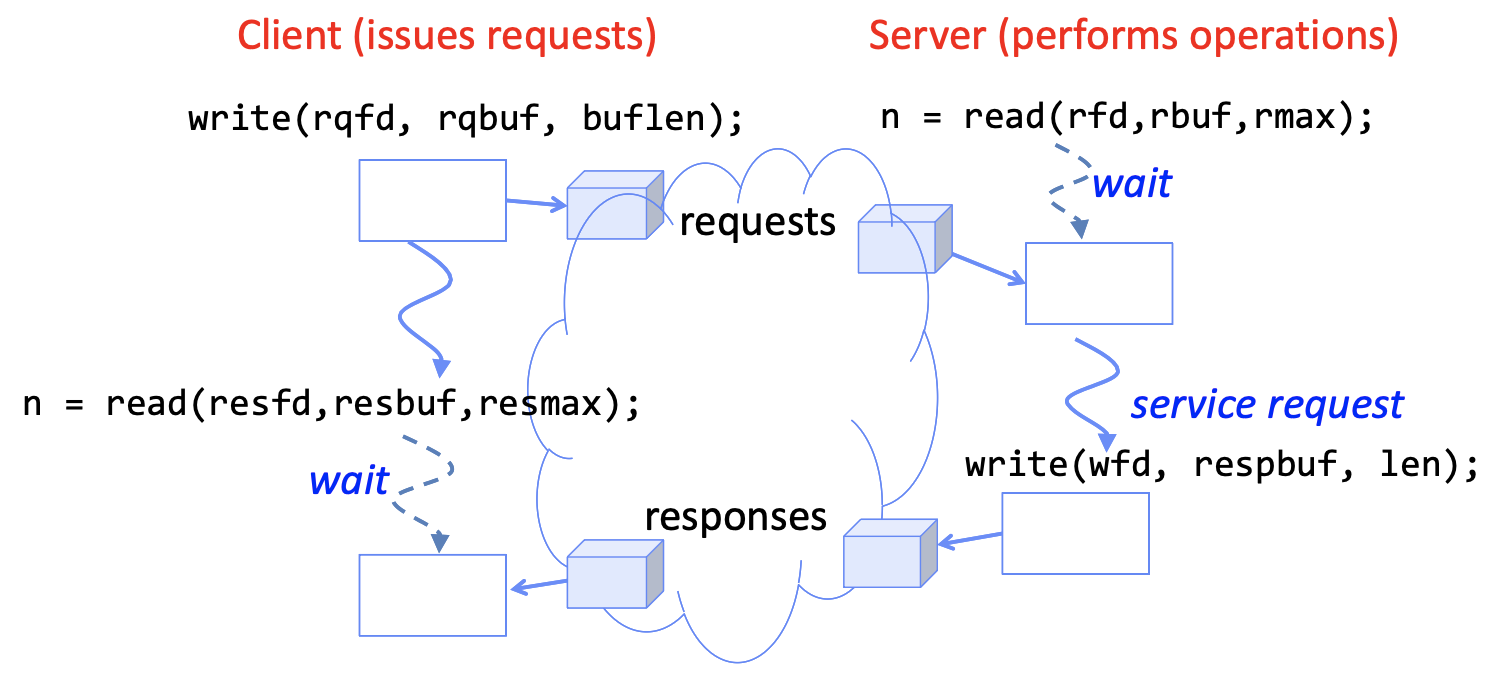
Request-Response Protocol
这是client-server模型的基础。简单理解就是client 写请求,server 读请求并处理,再写响应,client 读响应
Socket
这是这次Note的重点抽象,是IPC的一种机制,而且是可以跨机器的IPC,在原课件中的定义为:
Socket is an abstraction for one endpoint of a network connection.
socket看起来像是一个文件,它有fd,可以read,可以write,但它实际上是一对队列: 其中含有output queue存储发往对方的数据,也有input queue接受从对方发来的数据。相对应的write()就是往对方发送数据,read()就是从对方接受数据。同时要注意的一点是:
lseek()对于socket没意义,因为socket不是可随机访问文件
Echo Server Example
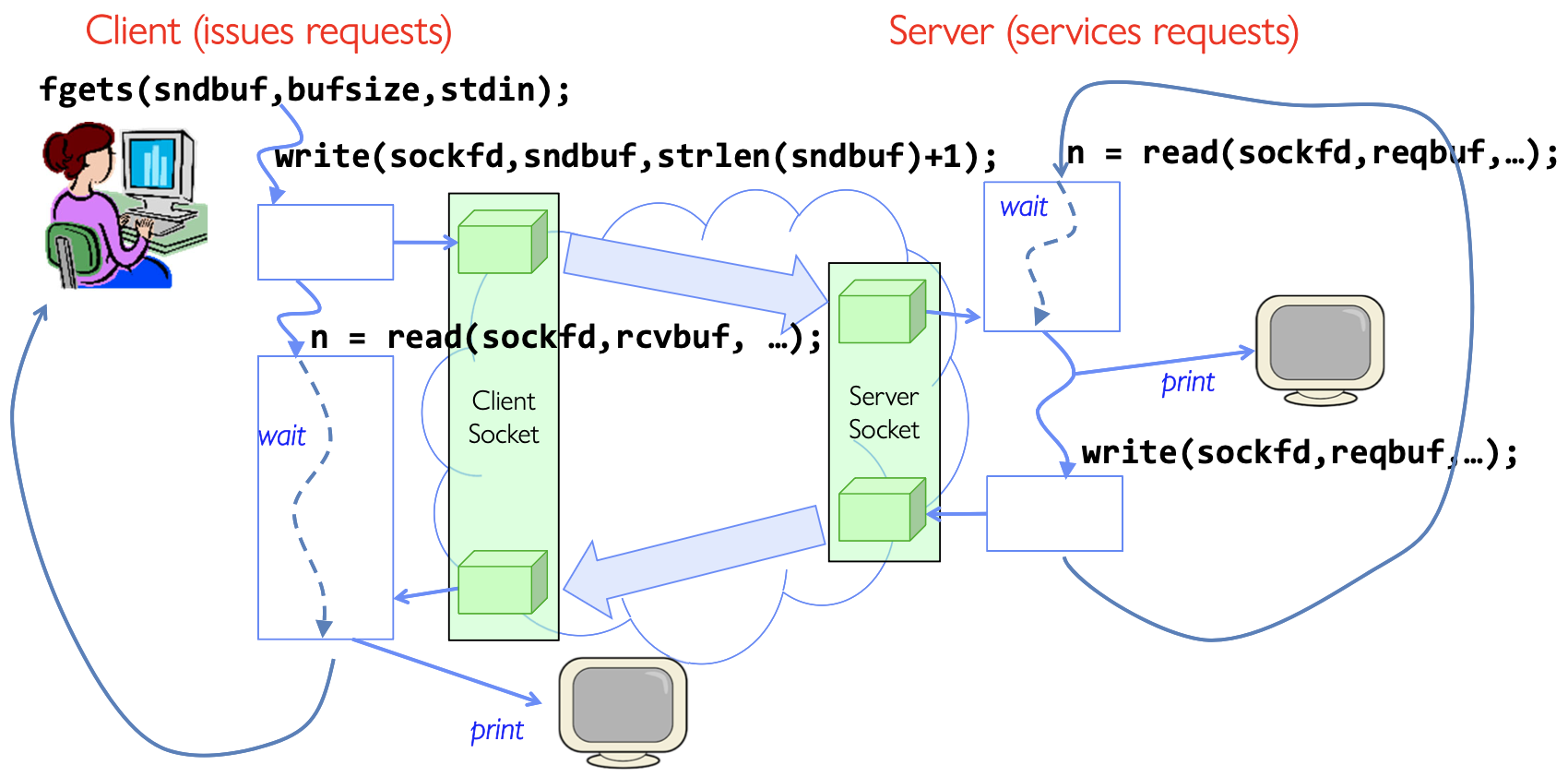
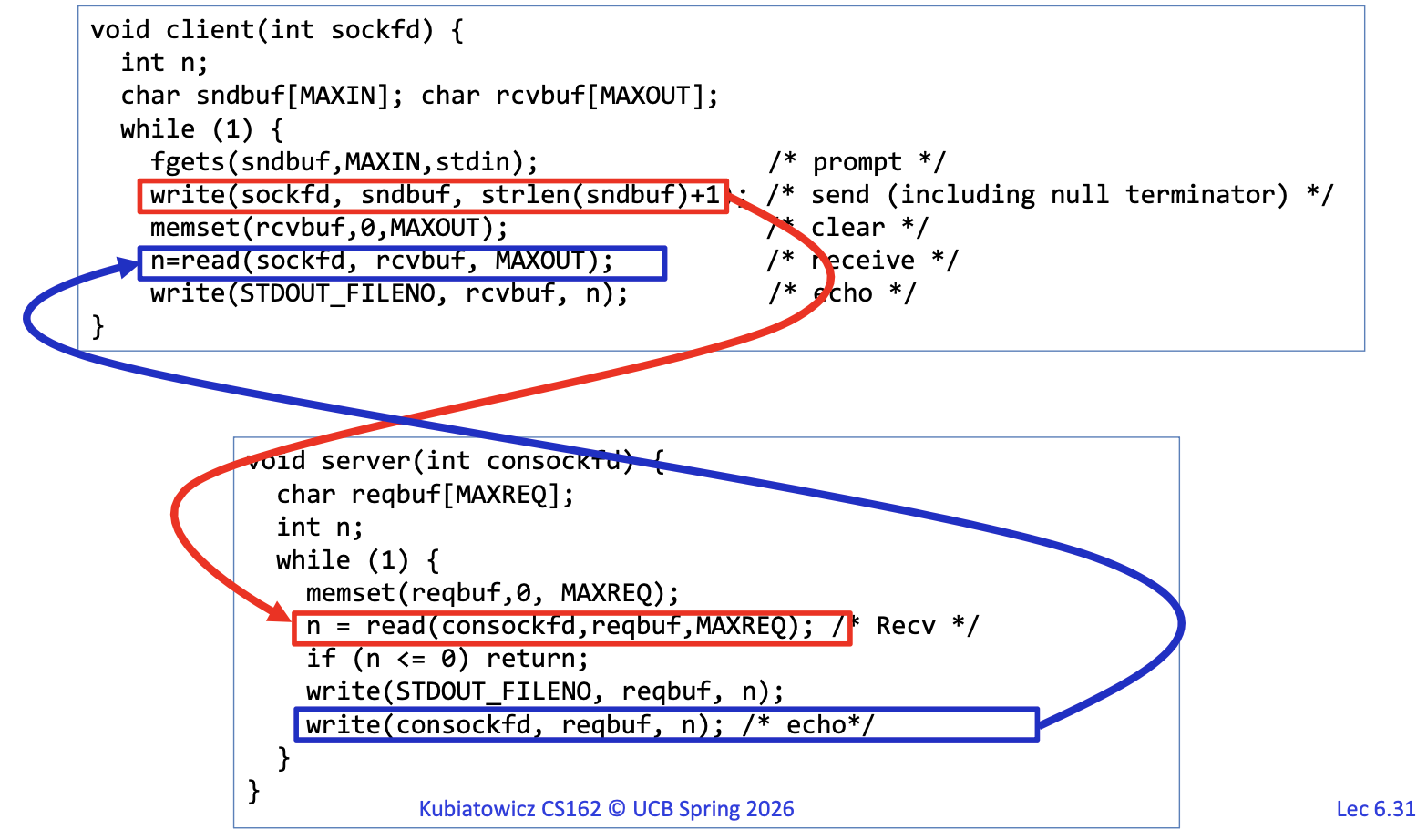 我们注意一下代码逻辑:
我们注意一下代码逻辑:
- Client循环做:
- 从标准行输入读取一行
write(sockfd, ...)发送给服务器read(sockfd, ...)读取服务器回显- 输出到标准输出
- Server循环做:
read(consockfd, ...)收请求- 如果读不到数据就结束
- 把数据打印到stdout
write(consockfd, ...)按照原样再发回去
这个例子我们假设了什么?
(1) Reliable
假设 TCP 是可靠的:
- 写出去的数据不会丢
- 另一端能按原样收到
(2) In order
假设顺序不乱:
- 先写 X 再写 Y
- 另一边先读到 X 再读到 Y
(3) Blocking behavior
如果还没有数据到达,read() 会阻塞。
这意味着程序会“等”。
Pipe Vs Socket Vs File

TCP/IP Connection Setup
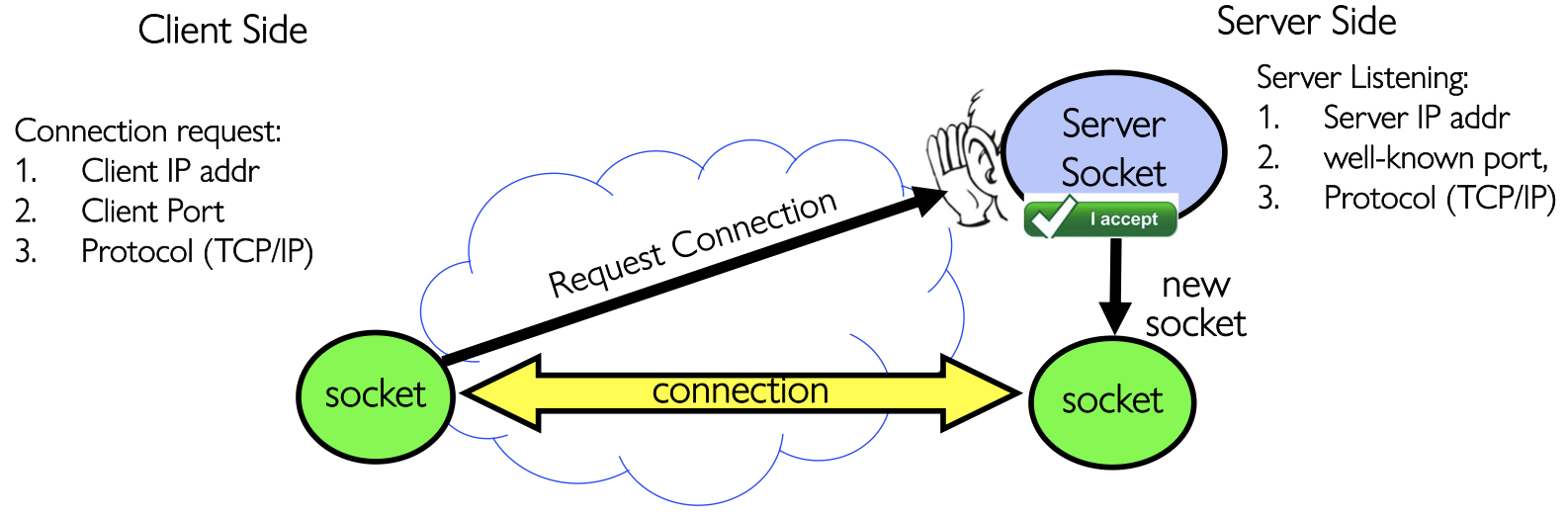 Server socket 就是一种特殊的
Server socket 就是一种特殊的Socket,有fd,但不能直接进行read(),write(),它真正进行的工作是listen()和accept()。
其中两个Socket也要进行区分,Listening socket负责监听连接,不能拿来收发应用层数据;Connected socket真正用于和某个client通信
同时课件还给出了5-Tuple 标识,它用来建立TCP connection:
- 1.Source IP Address
- 2.Destination IP Adress
- 3.Source Port Number
- 4.Destination Port Number
- 5.Protocol(Always TCP here)
同时告诉了我们客户端端口通常由
OS随机分配,但是服务器端口通常是well known:比如80:HTTP,443:HTTPS,25:SMTP
Client Server
下面给出了一个Web Server的基本流程图,我们要针对代码来进行深度解析
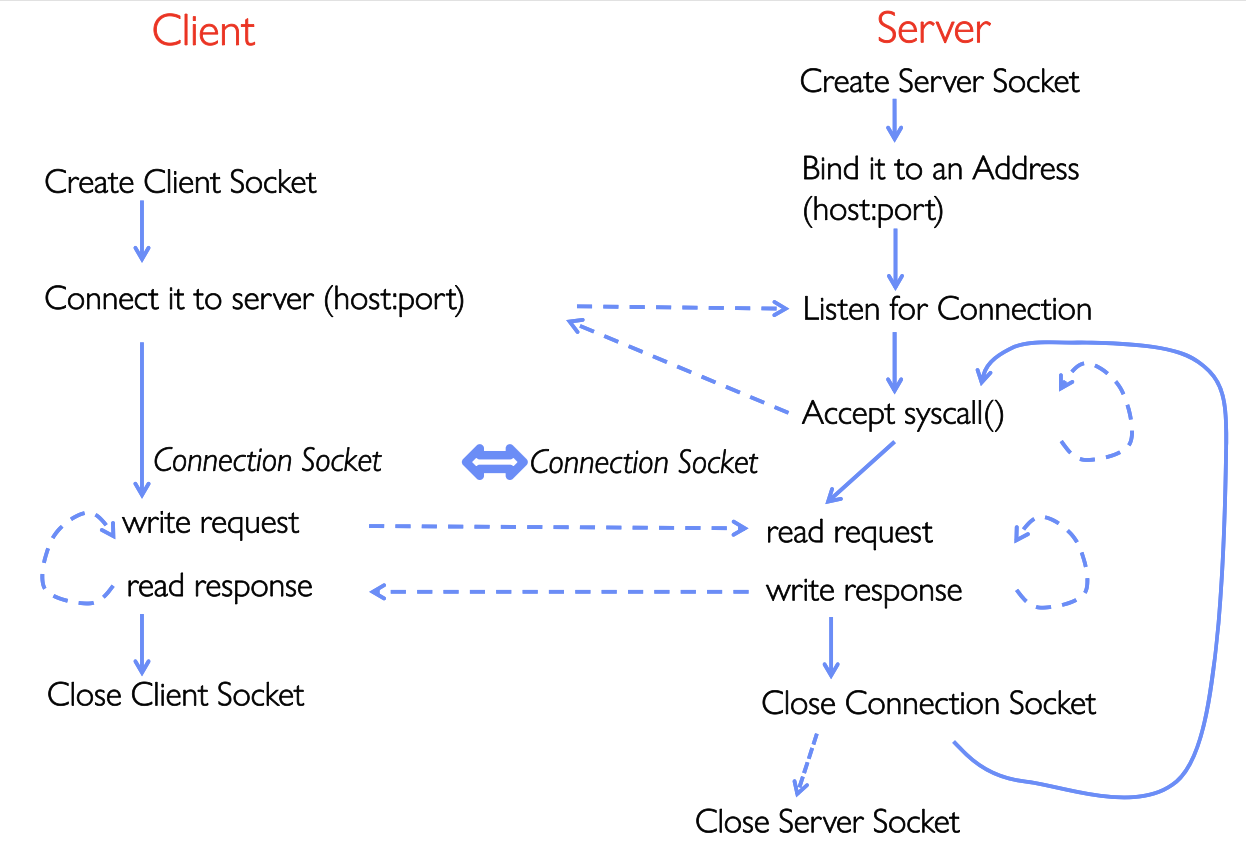
Client Code
char *host_name, *port_name;
// Create a socket
struct addrinfo *server = lookup_host(host_name, port_name);
int sock_fd = socket(server->ai_family, server->ai_socktype,server->ai_protocol);
// Connect to specified host and port
connect(sock_fd, server->ai_addr, server->ai_addrlen);
// Carry out Client-Server protocol
run_client(sock_fd);
/* Clean up on termination */
close(sock_fd);实现代码如下,注意函数getaddrinfo():当客户端获取服务器地址的时候,会用该函数
struct addrinfo *lookup_host(char *host_name, char *port) {
struct addrinfo *server;
struct addrinfo hints;
memset(&hints, 0, sizeof(hints));
hints.ai_family = AF_UNSPEC; /* Includes AF_INET and AF_INET6 */
hints.ai_socktype = SOCK_STREAM;/* Essentially TCP/IP */
int rv = getaddrinfo(host_name, port_name, &hints, &server);
if (rv != 0) {
printf("getaddrinfo failed: %s\n", gai_strerror(rv));
return NULL;
}
return server;
}AF_UNSPEC:支持 IPv4 和 IPv6SOCK_STREAM:表示 TCP stream socket
Server Code
函数调用部分:VERSION1
// Create socket to listen for client connections
char *port_name;
struct addrinfo *server = setup_address(port_name);
int server_socket = socket(server->ai_family, server->ai_socktype, server->ai_protocol);
// Bind socket to specific port必须绑定一个明确端口,客户端才知道连接哪里
bind(server_socket, server->ai_addr, server->ai_addrlen);
// Start listening for new client connections让socket
// 进入监听状态,开始允许客户端连接。这时候socket变成一个listing socket
listen(server_socket, MAX_QUEUE);
while (1) {
// Accept a new client connection, obtaining a new socket
// 从等待队列中取出一个连接请求,创建一个新的connected socket并返回新socket的fd
int conn_socket = accept(server_socket, NULL, NULL);
serve_client(conn_socket);
close(conn_socket);
}
close(server_socket);函数实现部分:
struct addrinfo *setup_address(char *port) {
struct addrinfo *server;
struct addrinfo hints;
memset(&hints, 0, sizeof(hints));
hints.ai_family = AF_UNSPEC; /* Includes AF_INET and AF_INET6 */
hints.ai_socktype = SOCK_STREAM; /* Essentially TCP/IP */
hints.ai_flags = AI_PASSIVE; /* Set up for server socket 不指定具体IP*/
int rv = getaddrinfo(NULL, port, &hints, &server); /* No address! (any local IP) */
if (rv != 0) {
printf("getaddrinfo failed: %s\n", gai_strerror(rv));
return NULL;
}
return server;
}Server Protection
然后我们继续深入思考,每个Server该怎么保护自己?答案就是每个连接用一个独立进程处理。因为如果每个client连接都在单独子进程中处理,逻辑就可以被隔离。如果一个请求崩了,至少不容易带着主Server一起跨掉,这种思想类似于沙箱思想。这时候我们就想到了之前在Note3中提及到的fork()
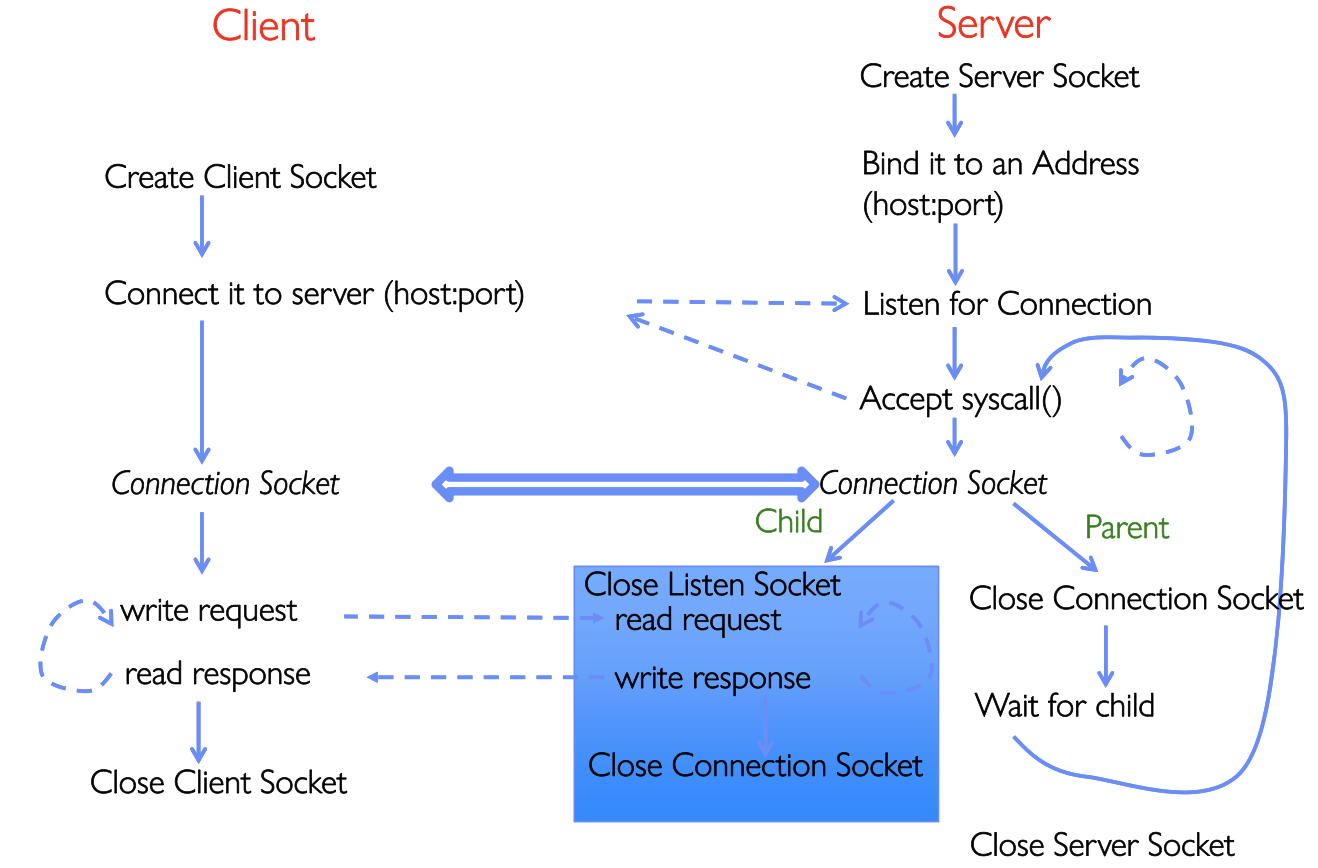 Server Code: VERSION2
Server Code: VERSION2
// Socket setup code elided…
listen(server_socket, MAX_QUEUE);
while (1) {
// Accept a new client connection, obtaining a new socket
int conn_socket = accept(server_socket, NULL, NULL);
pid_t pid = fork();
if (pid == 0) {
// 关闭监听socket
close(server_socket);
serve_client(conn_socket);
// 关闭连接socket
close(conn_socket);
exit(0);
} else {
// 关闭父进程自己的conn_socket
close(conn_socket);
// 等待子进程结束
wait(NULL);
}
}
close(server_socket);这里课件中提了一个问题:为什么父子进程都要close某些fd?
因为fork()会复制多余的文件描述符,如果不关闭多余的引用就会导致资源泄漏,并且Socket的生命周期也会异常,连接也可能迟迟不关闭
Concurrent Server
我们继续思考,VERSION2虽然有了保护性,但是父进程一直在wait(NULL)等待子进程结束:这就意味着必须等待当前client处理完毕,才能处理下一个连接。资源利用率太低了,我们的方向是把它变成并发→ Concurrent Server
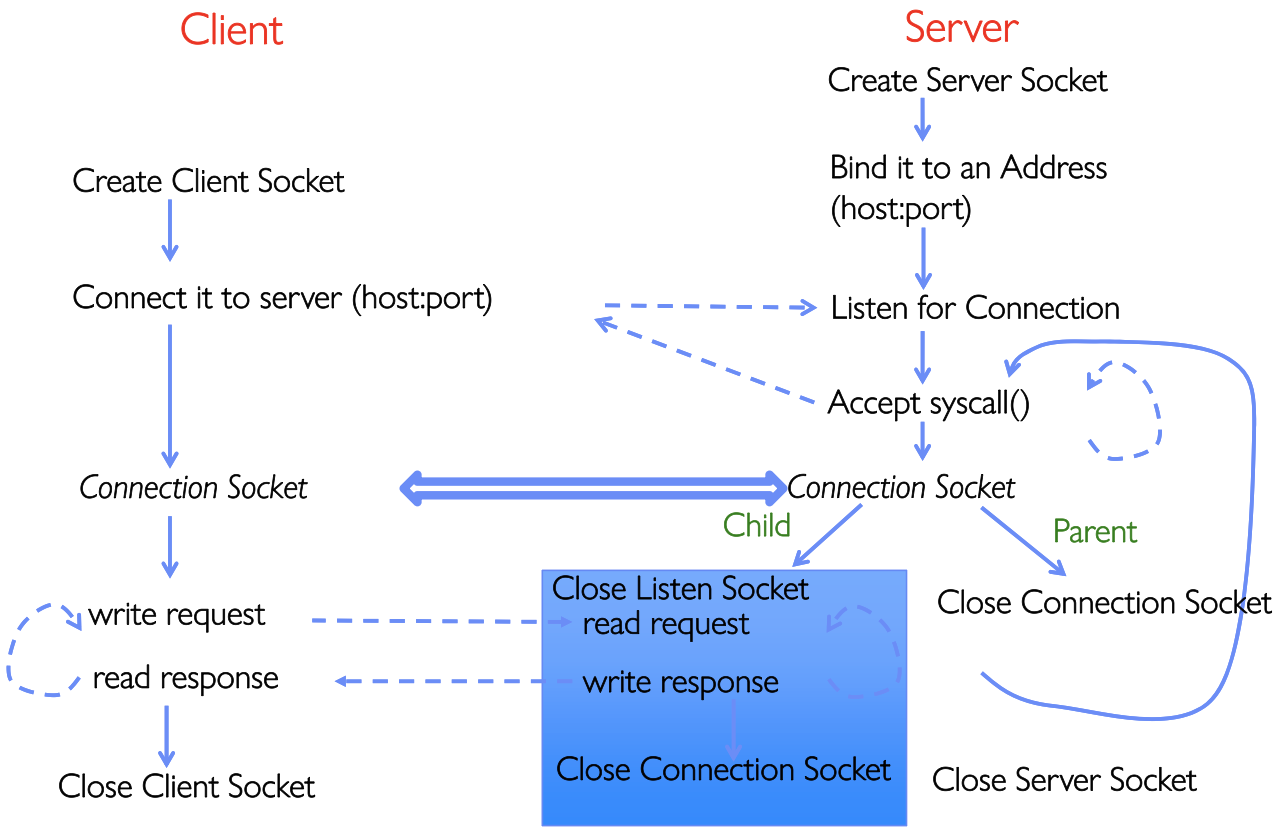 我们的思路就是父进程不再等待子进程了,父进程继续
我们的思路就是父进程不再等待子进程了,父进程继续accept()新连接,子进程并行处理旧连接。
思路很好,但是这样做是有代价的。当子进程过多的时候虽然地址空间隔离较好,但是仍然可能通过文件系统发生种种冲突。所以实现并发不是删掉wait(NULL)就实现了的。
Server Code:VERSION3
// Socket setup code elided…
listen(server_socket, MAX_QUEUE);
while (1) {
// Accept a new client connection, obtaining a new socket
int conn_socket = accept(server_socket, NULL, NULL);
pid_t pid = fork();
if (pid == 0) {
close(server_socket);
serve_client(conn_socket);
close(conn_socket);
exit(0);
} else {
close(conn_socket);
//wait(NULL);
}
}
close(server_socket);Faster Concurrent Server
课件里面给我们介绍了一个更快的方法,但是缺点是没有了保护机制
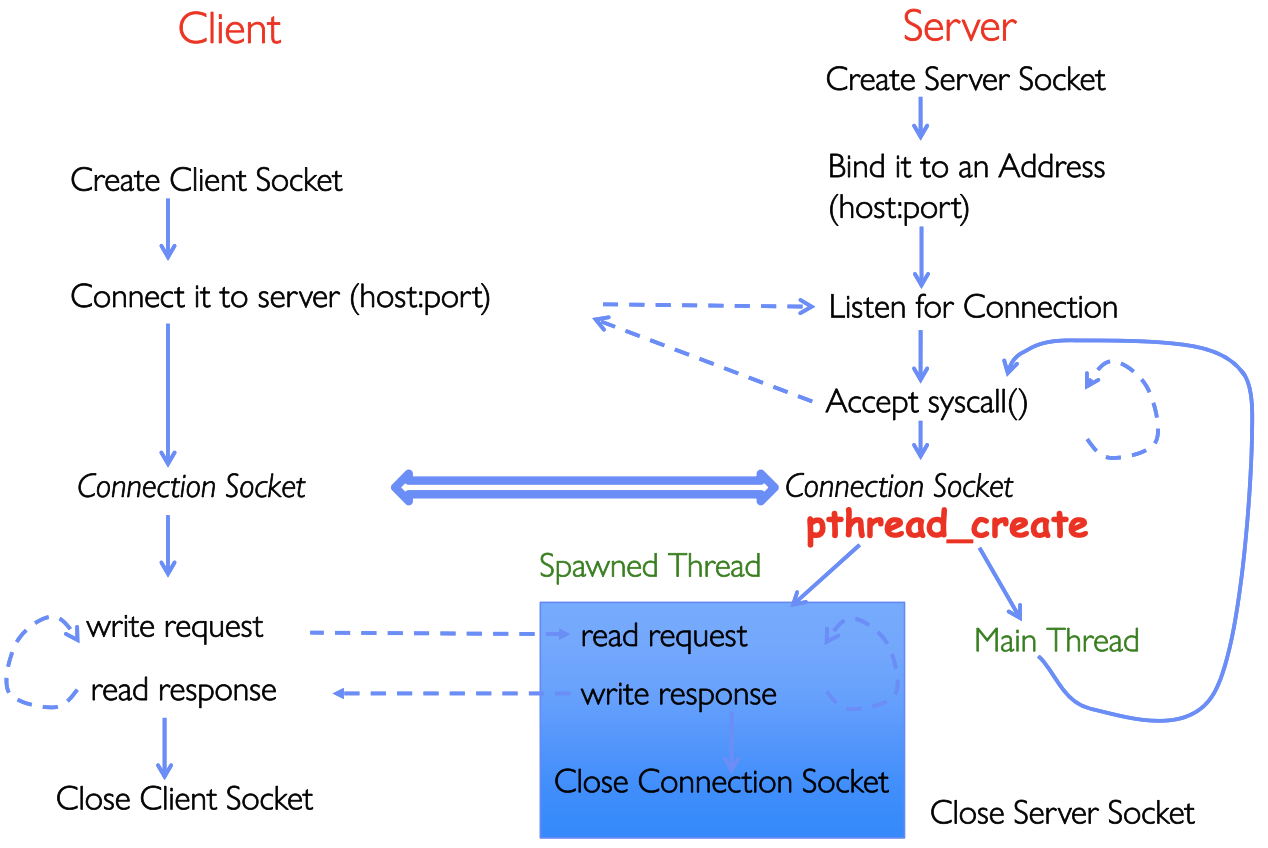 原理就是每个连接用一个线程,而不是一个进程。创建线程本来开销就更小,不必再耗费资源创建进程。同时线程切换更方便,耗费资源少。
但是缺点也很明显,没有独立进程的保护并且关键的是所有线程共享地址空间。
这里也引出了一个问题,当一个web-site太过于火爆,线程数有可能无限增长。当访问量过大的时候管理成本就暴涨,上下文切换又变多。这时候就需要线程池这个东西来限制最大并发线程数量:
原理就是每个连接用一个线程,而不是一个进程。创建线程本来开销就更小,不必再耗费资源创建进程。同时线程切换更方便,耗费资源少。
但是缺点也很明显,没有独立进程的保护并且关键的是所有线程共享地址空间。
这里也引出了一个问题,当一个web-site太过于火爆,线程数有可能无限增长。当访问量过大的时候管理成本就暴涨,上下文切换又变多。这时候就需要线程池这个东西来限制最大并发线程数量:
Thread Pools
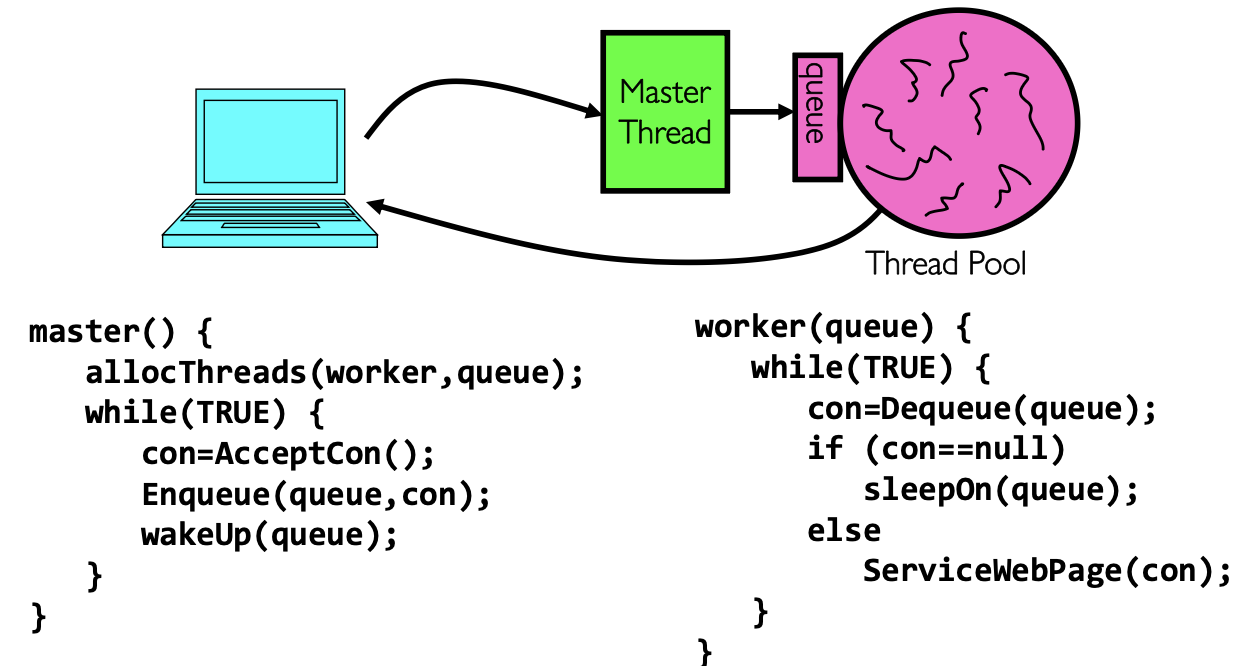 Master thread
Master thread
- 接收连接
- 放入 queue
- 唤醒 worker Worker thread
- 从 queue 取连接
- 处理请求
- 没活就睡眠等待