Everything is a File
如题,这句话是一句非常强的抽象,这也是Unix能形成强大生态的一个重要原因。
Unix/POSIX 的核心思想之一是:为不同类型的资源提供统一接口。这个统一接口就是建立在以下四个系统调用上: open(),read(),write(),close。此外补充了一个接口ioctl(),这个接口用于那些不太适合塞进read/write的定制化控制操作。
一旦“文件,设备,socket,pipe”都能通过相似接口调用,程序设计就会简单很多
File
在原文档中,File在文件系统抽象中的定义是:
A named collection of data in a file system
同时POXIS把file data看成一系列的bytes,也就是说操作系统在抽象层面不关心装的是什么格式的数据,不管是text,还是binary,它只能看见字节流。
这里再介绍一下metadata,它里面存储着关于文件的信息,例如: size, modification time,owner,security information,access control.data就是文件内容本身,metadata是关于文件的信息。
I/O And Storage Layers
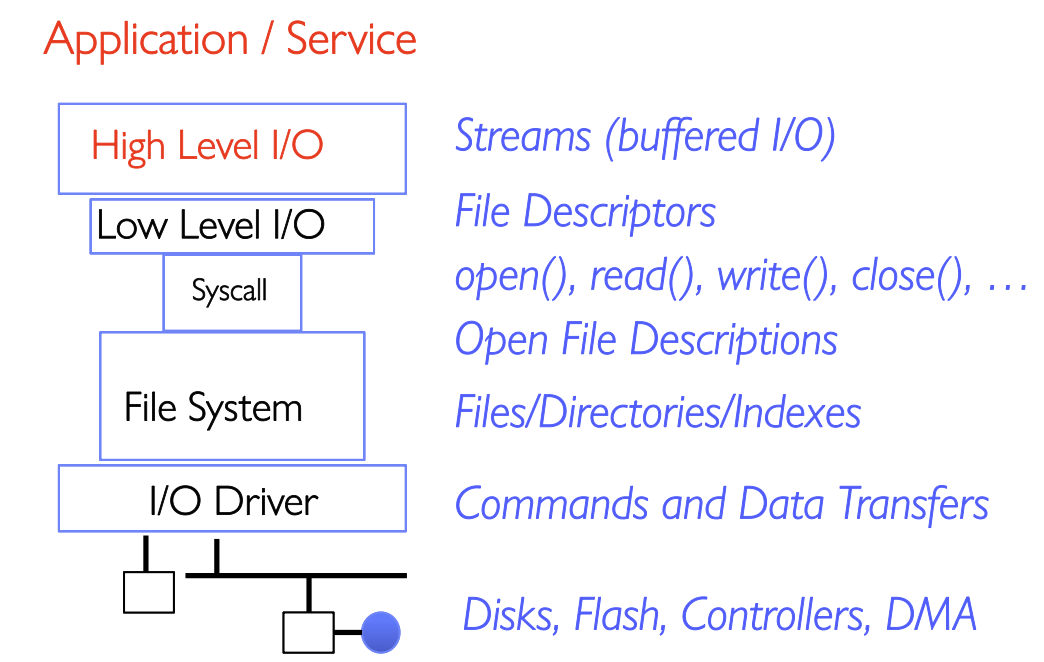 这里我们先大概了解一下构造,下面会细致的讲一部分。只需注意到
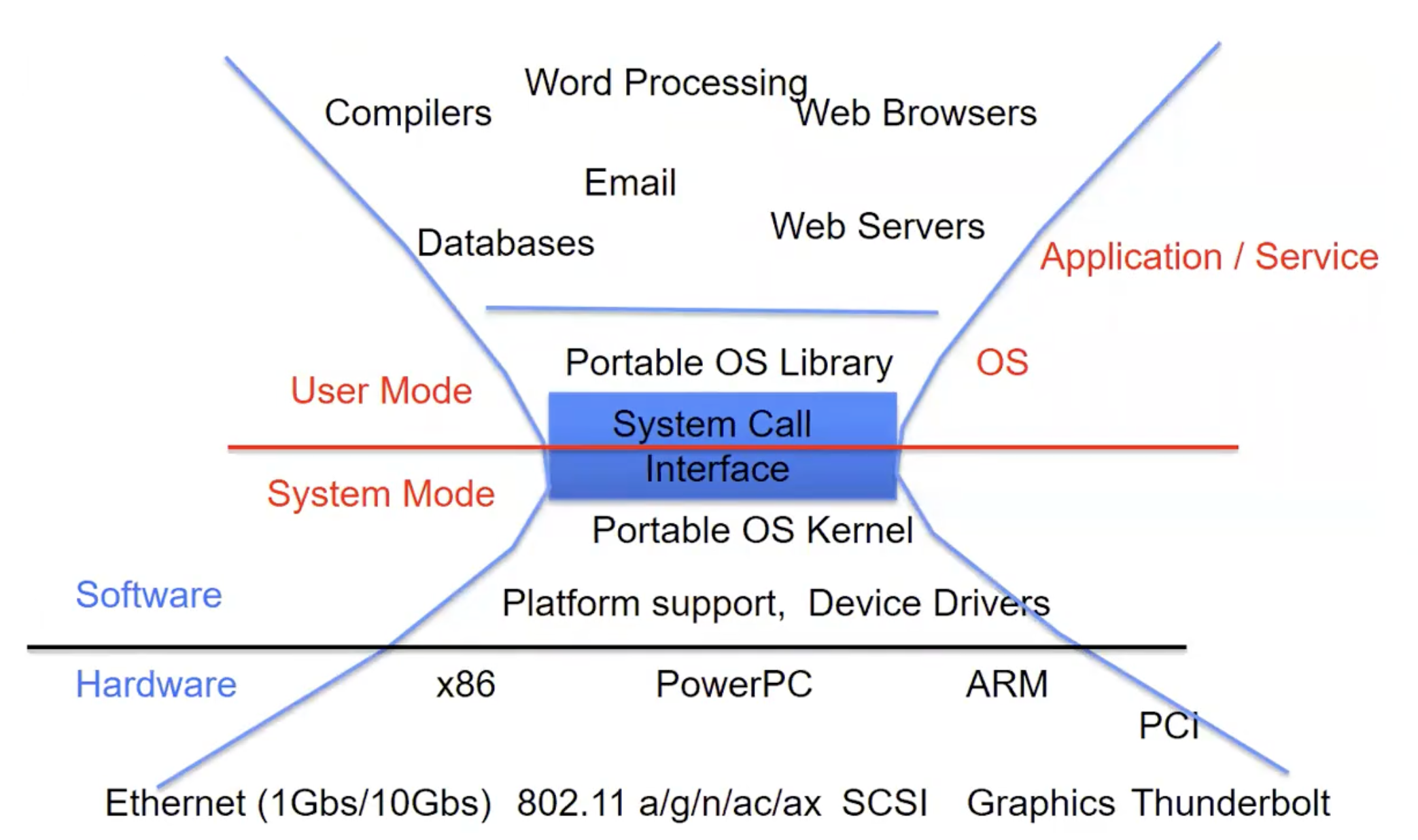
这里我们先大概了解一下构造,下面会细致的讲一部分。只需注意到Syscall是用户态进入内核态的正式入口,应用代码不能直接操作内核对象,只能通过syscall让内核代为执行。这个图和我们之前在Note3看到过的下面这张图有异曲同工之妙
High-Level I/O
Stream And FILE*
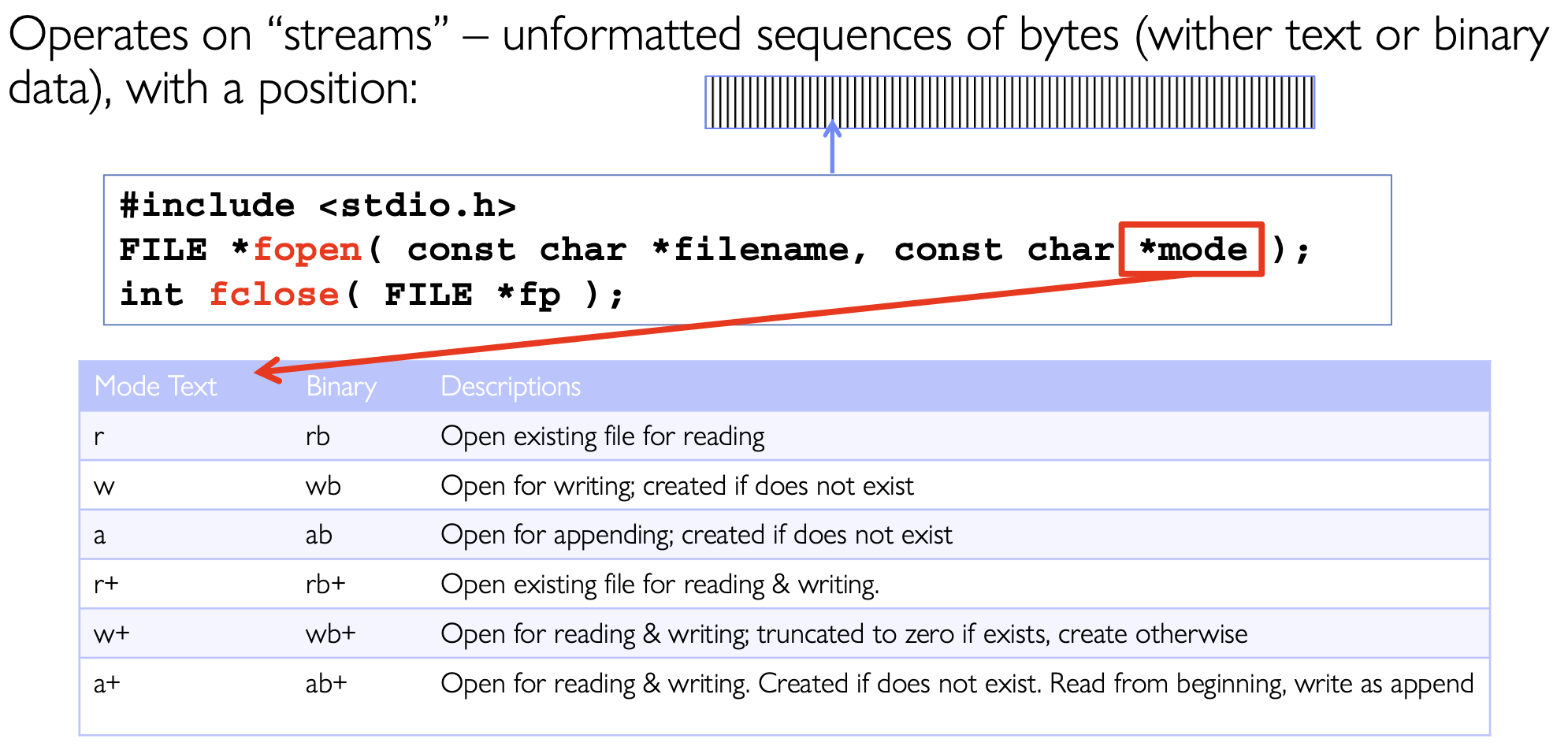
C高层文件API操作的是stream,讲义中对于stream的定义是:
Operates on “streams” – unformatted sequences of bytes (wither text or binary data), with a position
同时在高层接口里,一个打开的stream用FILE*表示,本质上指向了一个用户态的FILE结构,这其中维护了buffer,当前状态,底层fd等信息
Standard Streams
程序运行时,系统会默认打开3个标准流,如下图所示
Unix工具组合能力很强,就是因为这个标准流可以被重定向,比如下面的这个例子:
cat hello.txt | grep "World!"这里cat的stdout会连接到grep的stdin,这个机制是 shell pipeline的基础。
同时我们注意一下stderr,这个标准流通常用于输出诊断和错误信息,这样即使stdout被重定向到别的程序或文件,错误信息仍然可以单独处理。
C High-Level File API
原文档把高层控制读写类型API分为三类,其中Stream Positioning是位置控制API:
Character-oriented I/O
int fputc(int c, FILE *fp);
int fputs(const char *s, FILE *fp);
int fgetc(FILE *fp);
char *fgets(char *buf, int n, FILE *fp);这类适合逐字符或者逐行处理文本
Block-oriented I/O
size_t fread(void *ptr, size_t size_of_elements,
size_t number_of_elements, FILE *a_file);
size_t fwrite(const void *ptr, size_t size_of_elements,
size_t number_of_elements, FILE *a_file);我们和上面的Character-oriented I/O对比一下,在系统编程里,block I/O通常比char I/O更加实用。本质原因是Block-by-Block可以减少函数调用次数和数据搬运次数
Formatted I/O
int fprintf(FILE *stream, const char *format, ...);
int fscanf(FILE *stream, const char *format, ...);这类适合格式化输入输出
Stream Positioning
高层API还支持移动文件位置:
int fseek(FILE *stream, long int offset, int whence);
long int ftell(FILE *stream);
void rewind(FILE *stream);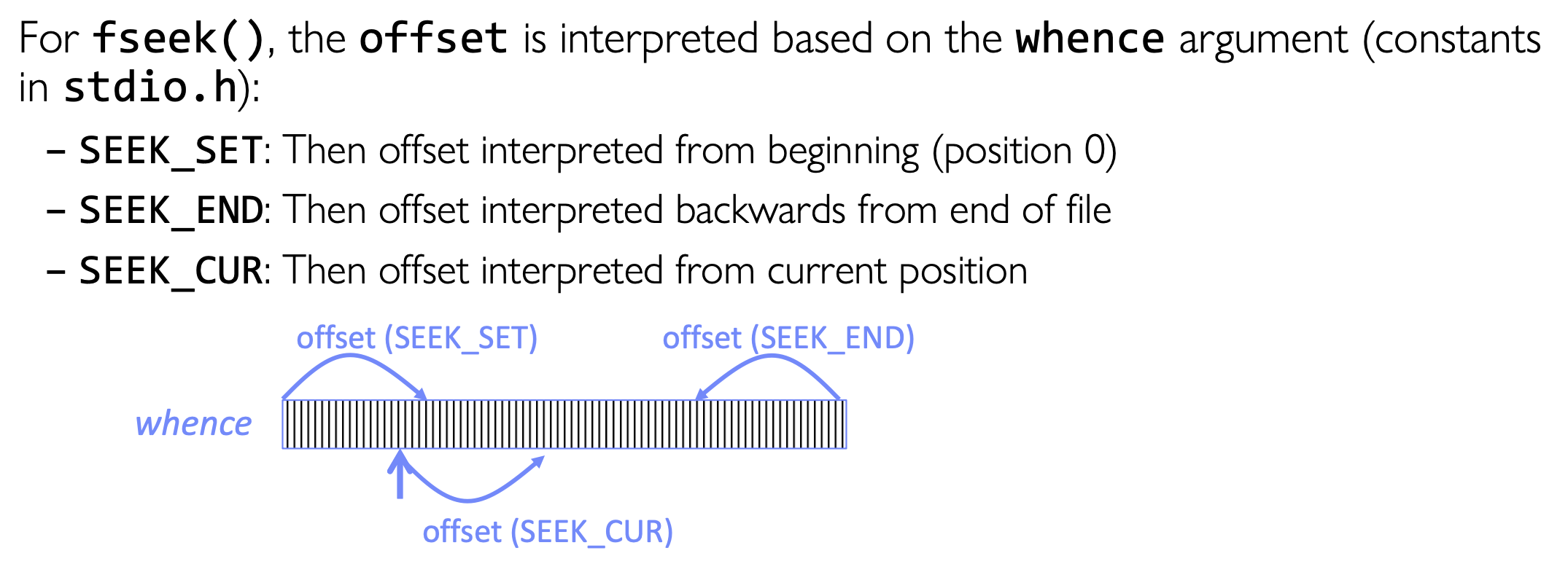
SEEK_SET:从文件开头开始偏移SEEK_END:从文件末尾开始偏移SEEK_CUR:从当前位置开始偏移 文件不是只能从头读到尾,操作系统允许你把文件当成一个带cursor/position的字节流来随机访问
Low-Level I/O
低层文件I/O直接对应系统调用接口,和High-Level I/O最大的差异在于:
High-Level返回FILE*Low-Level返回的是file descriptor(fd),本质上是一个整数(int) 这里我们详细解释一下,为什么fd是int类型的,不是指针:- 我们的初衷就是为了不让用户直接接触内核,所以说用户程序不应该拿到内核地址
- 内核对象也不能直接暴露给用户程序
fd只是进程视角下的handle或者说是索引
Pre-opened Standard Descriptors
在Low-Level I/O中,标准输入输出错误也有固定的fd:
STDIN_FILENO = 0STDOUT_FILENO = 1STDERR_FILENO = 2这和我们在上面提及到的stderr是相对应的。这种思想在转换接口中也有体现:
int fileno(FILE *stream);
FILE *fdopen(int filedes, const char *opentype);fileno()函数从FILE*拿到底层的fd,然后fdopen()把已有的fd包装成FILE*stream
这正是说明了High-Level和Low-Level不是完全割裂的两套世界,他们可以互相转换
Low-Level File API
read()
ssize_t read(int filedes, void *buffer, size_t maxsize);表示的是最多读maxsize字节,然而实际可能读的更少。因为实际文件字节数比maxsize小。该函数返回0表示EOF;返回-1表示ERROR
write()
ssize_t write(int filedes, const void *buffer, size_t size);返回实际写入的字节数,出错返回-1。可能写不完全部数据,所以必要时会循环写
lseek()
off_t lseek(int filedes, off_t offset, int whence);它在内核里面调整file offset,讲义里面特别强调:
这个 offset 独立于 high-level
FILE *在用户态维护的位置。
这也提醒了我们不要随意混用Low-Level和High-Level的定位逻辑,否则很容易把缓冲和偏移搞乱掉
Example
lowio.c
int main() {
char buf[1000];
int fd = open("lowio.c", O_RDONLY, S_IRUSR | S_IWUSR);
ssize_t rd = read(fd, buf, sizeof(buf));
int err = close(fd);
ssize_t wr = write(STDOUT_FILENO, buf, rd);
}这个程序最多读取sizeof(buf)这么多字节,也就是一次最多1000个字节。它并非把整个文件全部读完,而是只读了一批。read()一次调用不保证把全部想要的内容都处理完
POSIX I/O
What is POSIX?
POSIX = Portable Operating System Interface。
它本质上是一组标准接口规范,主要面向应用程序开发者。它的目标是让不同 Unix-like 系统在接口层尽可能统一,从而让应用具有更好的 portability。
可以这样理解:
- Unix 系统很多,不同系统实现细节可能不同;
- 但如果它们都遵守 POSIX 接口规范;
- 那程序就可以更容易跨系统迁移。 所以在操作系统课程里,很多 API 看起来像“Linux API”,其实更准确说是 POSIX-style interface。
POSIX I/O: Design Patterns
Open before use
先 open 再使用。
因为访问控制检查、打开状态建立等工作都在这个阶段完成。
Byte-oriented
POSIX I/O 以 byte-oriented 为核心。
这是“least common denominator”的设计:
不管底层是真正按块工作的磁盘,还是其他设备,OS 都把它们统一包装成字节读写模型。
Explicit close
用完显式 close。
这不仅是资源管理习惯,也和缓冲刷新、内核资源释放、引用计数等有关。
Kernel Buffering
在内核中读操作会被做缓冲:
- 原因之一是为了维持
byte-oriented abstraction - 进程等待设备时会被阻塞,而操作系统可以去运行别的进程 在内核中写操作也会被做缓冲:
write()返回时常常意味数据已经移交给了内核,而不是一定真的落到了物理设备上
Kernel做Buffer的好处
- hide device granularity
- improve throughput
- support caching
- reduce direct hardware wait time
High-Level vs Low-Level File API

两个个典型对比
第一个:
- 使用
read()每次取 4 bytes,如果循环中每次read()只读 4 字节,那么每次都要进入内核,开销非常大 - 使用
fread()每次取 4 bytes,第一次fread()可能触发一次真正的read(),例如先从内核读 1024 字节进 buffer,之后很多次fread()都只是从用户态 buffer 里拿数据。 第二个: High-Level buffered stream example:
printf("Beginning of line ");
sleep(10);
printf("and end of line\n");这可能在10秒后一次性全部输出,因为stream在用户空间有缓冲
Low-level descriptor example:
write(STDOUT_FILENO, "Beginning of line ", 18);
sleep(10);
write(STDOUT_FILENO, "and end of line\n", 16);这里第一段会立刻可见,第二段10秒后再出现。因为write()的效果在接口层面更加立即可见
Below The Surface
当你只觉得调用fread(),read(),write()很简单的等等函数时,但底层实际发生的是:
- high-level 先检查用户态 buffer
- 如果 buffer 不够,再调用 low-level syscall
- 参数通过寄存器设置
- 执行
syscall指令 - 进入 kernel
- 内核分发到相应系统调用处理例程
- 文件系统、驱动、硬件完成实际操作
- 返回结果给用户程序 这是抽象层的核心价值:上层简单底层不简单